 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.
Dual-Balancing for Physics-Informed Neural Networks
May 19, 2025Physics-informed neural networks (PINNs) have emerged as a new learning paradigm for solving partial differential equations (PDEs) by enforcing the constraints of physical equations, boundary conditions (BCs), and initial conditions (ICs) into the loss function. Despite their successes, vanilla PINNs still suffer from poor accuracy and slow convergence due to the intractable multi-objective optimization issue. In this paper, we propose a novel Dual-Balanced PINN (DB-PINN), which dynamically adjusts loss weights by integrating inter-balancing and intra-balancing to alleviate two imbalance issues in PINNs. Inter-balancing aims to mitigate the gradient imbalance between PDE residual loss and condition-fitting losses by determining an aggregated weight that offsets their gradient distribution discrepancies. Intra-balancing acts on condition-fitting losses to tackle the imbalance in fitting difficulty across diverse conditions. By evaluating the fitting difficulty based on the loss records, intra-balancing can allocate the aggregated weight proportionally to each condition loss according to its fitting difficulty level. We further introduce a robust weight update strategy to prevent abrupt spikes and arithmetic overflow in instantaneous weight values caused by large loss variances, enabling smooth weight updating and stable training. Extensive experiments demonstrate that DB-PINN achieves significantly superior performance than those popular gradient-based weighting methods in terms of convergence speed and prediction accuracy. Our code and supplementary material are available at https://github.com/chenhong-zhou/DualBalanced-PINNs.
Learning Physics-Informed Color-Aware Transforms for Low-Light Image Enhancement
Apr 16, 2025
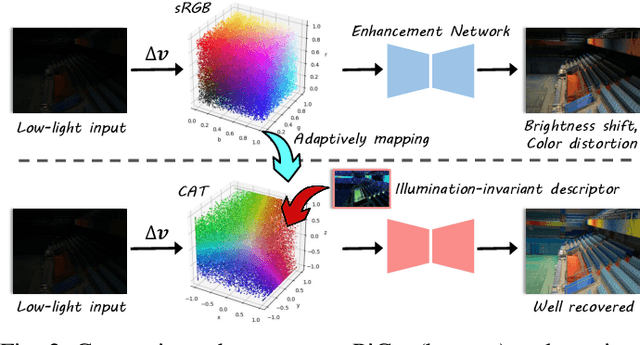


Image decomposition offers deep insights into the imaging factors of visual data and significantly enhances various advanced computer vision tasks. In this work, we introduce a novel approach to low-light image enhancement based on decomposed physics-informed priors. Existing methods that directly map low-light to normal-light images in the sRGB color space suffer from inconsistent color predictions and high sensitivity to spectral power distribution (SPD) variations, resulting in unstable performance under diverse lighting conditions. To address these challenges, we introduce a Physics-informed Color-aware Transform (PiCat), a learning-based framework that converts low-light images from the sRGB color space into deep illumination-invariant descriptors via our proposed Color-aware Transform (CAT). This transformation enables robust handling of complex lighting and SPD variations. Complementing this, we propose the Content-Noise Decomposition Network (CNDN), which refines the descriptor distributions to better align with well-lit conditions by mitigating noise and other distortions, thereby effectively restoring content representations to low-light images. The CAT and the CNDN collectively act as a physical prior, guiding the transformation process from low-light to normal-light domains. Our proposed PiCat framework demonstrates superior performance compared to state-of-the-art methods across five benchmark datasets.
Multi-scale Progressive Feature Embedding for Accurate NIR-to-RGB Spectral Domain Translation
Dec 26, 2023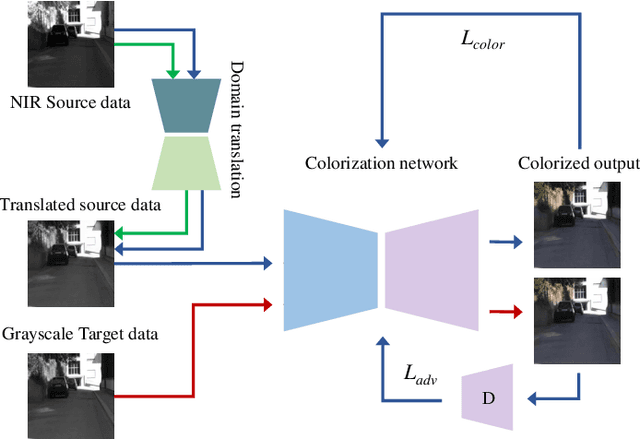



NIR-to-RGB spectral domain translation is a challenging task due to the mapping ambiguities, and existing methods show limited learning capacities. To address these challenges, we propose to colorize NIR images via a multi-scale progressive feature embedding network (MPFNet), with the guidance of grayscale image colorization. Specifically, we first introduce a domain translation module that translates NIR source images into the grayscale target domain. By incorporating a progressive training strategy, the statistical and semantic knowledge from both task domains are efficiently aligned with a series of pixel- and feature-level consistency constraints. Besides, a multi-scale progressive feature embedding network is designed to improve learning capabilities. Experiments show that our MPFNet outperforms state-of-the-art counterparts by 2.55 dB in the NIR-to-RGB spectral domain translation task in terms of PSNR.
Hyperspectral Image Reconstruction via Combinatorial Embedding of Cross-Channel Spatio-Spectral Clues
Dec 18, 2023Existing learning-based hyperspectral reconstruction methods show limitations in fully exploiting the information among the hyperspectral bands. As such, we propose to investigate the chromatic inter-dependencies in their respective hyperspectral embedding space. These embedded features can be fully exploited by querying the inter-channel correlations in a combinatorial manner, with the unique and complementary information efficiently fused into the final prediction. We found such independent modeling and combinatorial excavation mechanisms are extremely beneficial to uncover marginal spectral features, especially in the long wavelength bands. In addition, we have proposed a spatio-spectral attention block and a spectrum-fusion attention module, which greatly facilitates the excavation and fusion of information at both semantically long-range levels and fine-grained pixel levels across all dimensions. Extensive quantitative and qualitative experiments show that our method (dubbed CESST) achieves SOTA performance. Code for this project is at: https://github.com/AlexYangxx/CESST.
Cooperative Colorization: Exploring Latent Cross-Domain Priors for NIR Image Spectrum Translation
Aug 07, 2023Near-infrared (NIR) image spectrum translation is a challenging problem with many promising applications. Existing methods struggle with the mapping ambiguity between the NIR and the RGB domains, and generalize poorly due to the limitations of models' learning capabilities and the unavailability of sufficient NIR-RGB image pairs for training. To address these challenges, we propose a cooperative learning paradigm that colorizes NIR images in parallel with another proxy grayscale colorization task by exploring latent cross-domain priors (i.e., latent spectrum context priors and task domain priors), dubbed CoColor. The complementary statistical and semantic spectrum information from these two task domains -- in the forms of pre-trained colorization networks -- are brought in as task domain priors. A bilateral domain translation module is subsequently designed, in which intermittent NIR images are generated from grayscale and colorized in parallel with authentic NIR images; and vice versa for the grayscale images. These intermittent transformations act as latent spectrum context priors for efficient domain knowledge exchange. We progressively fine-tune and fuse these modules with a series of pixel-level and feature-level consistency constraints. Experiments show that our proposed cooperative learning framework produces satisfactory spectrum translation outputs with diverse colors and rich textures, and outperforms state-of-the-art counterparts by 3.95dB and 4.66dB in terms of PNSR for the NIR and grayscale colorization tasks, respectively.
Attention-Guided NIR Image Colorization via Adaptive Fusion of Semantic and Texture Clues
Jul 20, 2021



Near infrared (NIR) imaging has been widely applied in low-light imaging scenarios; however, it is difficult for human and algorithms to perceive the real scene in the colorless NIR domain. While Generative Adversarial Network (GAN) has been widely employed in various image colorization tasks, it is challenging for a direct mapping mechanism, such as a conventional GAN, to transform an image from the NIR to the RGB domain with correct semantic reasoning, well-preserved textures, and vivid color combinations concurrently. In this work, we propose a novel Attention-based NIR image colorization framework via Adaptive Fusion of Semantic and Texture clues, aiming at achieving these goals within the same framework. The tasks of texture transfer and semantic reasoning are carried out in two separate network blocks. Specifically, the Texture Transfer Block (TTB) aims at extracting texture features from the NIR image's Laplacian component and transferring them for subsequent color fusion. The Semantic Reasoning Block (SRB) extracts semantic clues and maps the NIR pixel values to the RGB domain. Finally, a Fusion Attention Block (FAB) is proposed to adaptively fuse the features from the two branches and generate an optimized colorization result. In order to enhance the network's learning capacity in semantic reasoning as well as mapping precision in texture transfer, we have proposed the Residual Coordinate Attention Block (RCAB), which incorporates coordinate attention into a residual learning framework, enabling the network to capture long-range dependencies along the channel direction and meanwhile precise positional information can be preserved along spatial directions. RCAB is also incorporated into FAB to facilitate accurate texture alignment during fusion. Both quantitative and qualitative evaluations show that the proposed method outperforms state-of-the-art NIR image colorization methods.
Attention-Guided Progressive Neural Texture Fusion for High Dynamic Range Image Restoration
Jul 13, 2021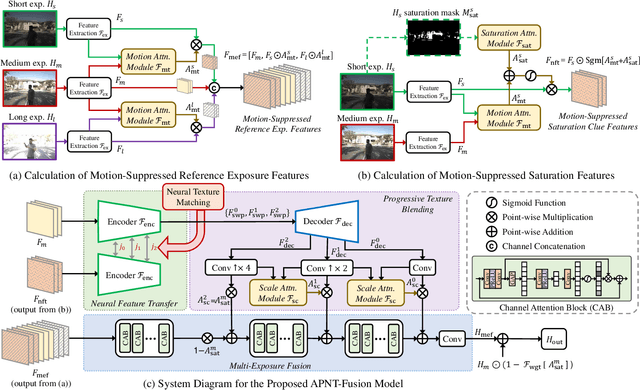
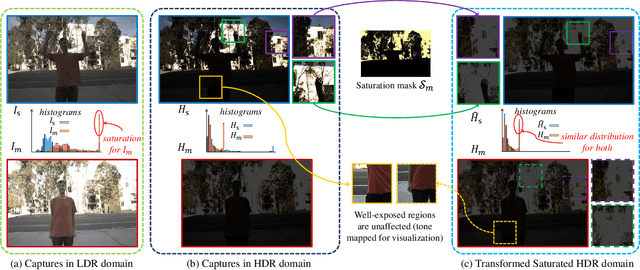
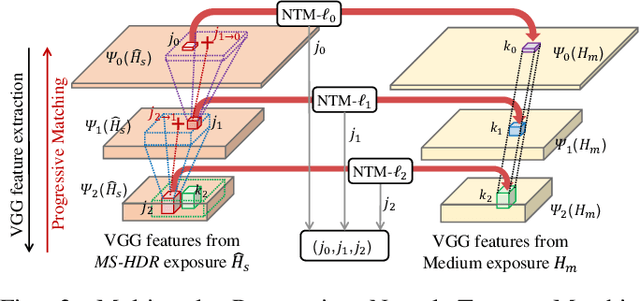
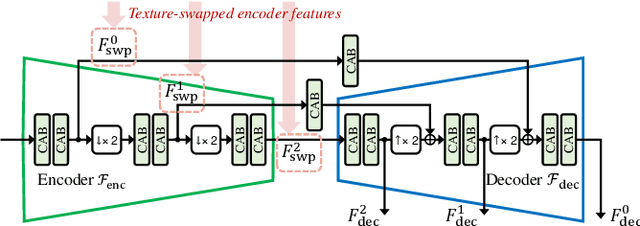
High Dynamic Range (HDR) imaging via multi-exposure fusion is an important task for most modern imaging platforms. In spite of recent developments in both hardware and algorithm innovations, challenges remain over content association ambiguities caused by saturation, motion, and various artifacts introduced during multi-exposure fusion such as ghosting, noise, and blur. In this work, we propose an Attention-guided Progressive Neural Texture Fusion (APNT-Fusion) HDR restoration model which aims to address these issues within one framework. An efficient two-stream structure is proposed which separately focuses on texture feature transfer over saturated regions and multi-exposure tonal and texture feature fusion. A neural feature transfer mechanism is proposed which establishes spatial correspondence between different exposures based on multi-scale VGG features in the masked saturated HDR domain for discriminative contextual clues over the ambiguous image areas. A progressive texture blending module is designed to blend the encoded two-stream features in a multi-scale and progressive manner. In addition, we introduce several novel attention mechanisms, i.e., the motion attention module detects and suppresses the content discrepancies among the reference images; the saturation attention module facilitates differentiating the misalignment caused by saturation from those caused by motion; and the scale attention module ensures texture blending consistency between different coder/decoder scales. We carry out comprehensive qualitative and quantitative evaluations and ablation studies, which validate that these novel modules work coherently under the same framework and outperform state-of-the-art methods.
Scale-Consistent Fusion: from Heterogeneous Local Sampling to Global Immersive Rendering
Jun 17, 2021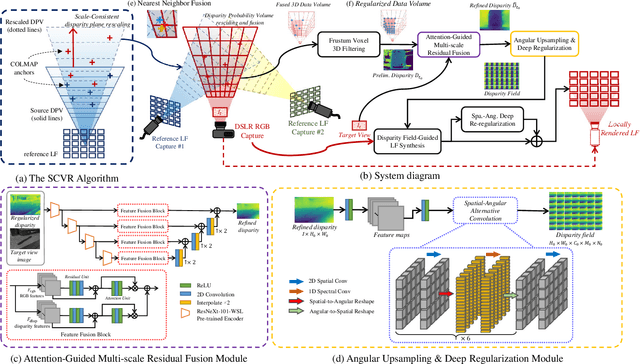



Image-based geometric modeling and novel view synthesis based on sparse, large-baseline samplings are challenging but important tasks for emerging multimedia applications such as virtual reality and immersive telepresence. Existing methods fail to produce satisfactory results due to the limitation on inferring reliable depth information over such challenging reference conditions. With the popularization of commercial light field (LF) cameras, capturing LF images (LFIs) is as convenient as taking regular photos, and geometry information can be reliably inferred. This inspires us to use a sparse set of LF captures to render high-quality novel views globally. However, fusion of LF captures from multiple angles is challenging due to the scale inconsistency caused by various capture settings. To overcome this challenge, we propose a novel scale-consistent volume rescaling algorithm that robustly aligns the disparity probability volumes (DPV) among different captures for scale-consistent global geometry fusion. Based on the fused DPV projected to the target camera frustum, novel learning-based modules have been proposed (i.e., the attention-guided multi-scale residual fusion module, and the disparity field guided deep re-regularization module) which comprehensively regularize noisy observations from heterogeneous captures for high-quality rendering of novel LFIs. Both quantitative and qualitative experiments over the Stanford Lytro Multi-view LF dataset show that the proposed method outperforms state-of-the-art methods significantly under different experiment settings for disparity inference and LF synthesis.