 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Consistent Fusion: from Heterogeneous Local Sampling to Global Immersive Rendering
Paper and Code
Jun 17, 2021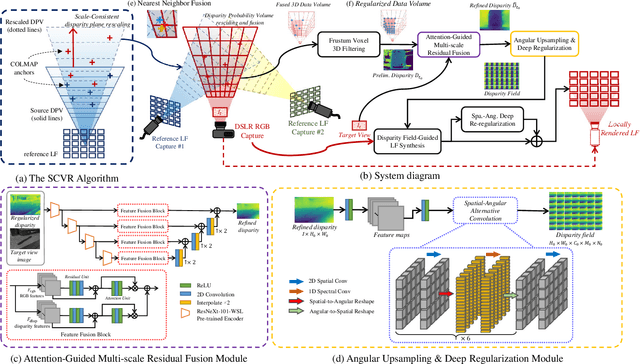



Image-based geometric modeling and novel view synthesis based on sparse, large-baseline samplings are challenging but important tasks for emerging multimedia applications such as virtual reality and immersive telepresence. Existing methods fail to produce satisfactory results due to the limitation on inferring reliable depth information over such challenging reference conditions. With the popularization of commercial light field (LF) cameras, capturing LF images (LFIs) is as convenient as taking regular photos, and geometry information can be reliably inferred. This inspires us to use a sparse set of LF captures to render high-quality novel views globally. However, fusion of LF captures from multiple angles is challenging due to the scale inconsistency caused by various capture settings. To overcome this challenge, we propose a novel scale-consistent volume rescaling algorithm that robustly aligns the disparity probability volumes (DPV) among different captures for scale-consistent global geometry fusion. Based on the fused DPV projected to the target camera frustum, novel learning-based modules have been proposed (i.e., the attention-guided multi-scale residual fusion module, and the disparity field guided deep re-regularization module) which comprehensively regularize noisy observations from heterogeneous captures for high-quality rendering of novel LFIs. Both quantitative and qualitative experiments over the Stanford Lytro Multi-view LF dataset show that the proposed method outperforms state-of-the-art methods significantly under different experiment settings for disparity inference and LF synthesis.