 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-guided exploration of active feature selection policies
Mar 16, 2026Determining the most appropriate features for machine learning predictive models is challenging regarding performance and feature acquisition costs. In particular, global feature choice is limited given that some features will only benefit a subset of instances. In previous work, we proposed a reinforcement learning approach to sequentially recommend which modality to acquire next to reach the best information/cost ratio, based on the instance-specific information already acquired. We formulated the problem as a Markov Decision Process where the state's dimensionality changes during the episode, avoiding data imputation, contrary to existing works. However, this only allowed processing a small number of features, as all possible combinations of features were considered. Here, we address these limitations with two contributions: 1) we expand our framework to larger datasets with a heuristic-based strategy that focuses on the most promising feature combinations, and 2) we introduce a post-fit regularisation strategy that reduces the number of different feature combinations, leading to compact sequences of decisions. We tested our method on four binary classification datasets (one involving high-dimensional variables), the largest of which had 56 features and 4500 samples. We obtained better performance than state-of-the-art methods, both in terms of accuracy and policy complexity.
Reinforcement Learning for Unsupervised Domain Adaptation in Spatio-Temporal Echocardiography Segmentation
Oct 16, 2025Domain adaptation methods aim to bridge the gap between datasets by enabling knowledge transfer across domains, reducing the need for additional expert annotations. However, many approaches struggle with reliability in the target domain, an issue particularly critical in medical image segmentation, where accuracy and anatomical validity are essential. This challenge is further exacerbated in spatio-temporal data, where the lack of temporal consistency can significantly degrade segmentation quality, and particularly in echocardiography, where the presence of artifacts and noise can further hinder segmentation performance. To address these issues, we present RL4Seg3D, an unsupervised domain adaptation framework for 2D + time echocardiography segmentation. RL4Seg3D integrates novel reward functions and a fusion scheme to enhance key landmark precision in its segmentations while processing full-sized input videos. By leveraging reinforcement learning for image segmentation, our approach improves accuracy, anatomical validity, and temporal consistency while also providing, as a beneficial side effect, a robust uncertainty estimator, which can be used at test time to further enhance segmentation performance. We demonstrate the effectiveness of our framework on over 30,000 echocardiographic videos, showing that it outperforms standard domain adaptation techniques without the need for any labels on the target domain. Code is available at https://github.com/arnaudjudge/RL4Seg3D.
Generation of realistic cardiac ultrasound sequences with ground truth motion and speckle decorrelation
Sep 05, 2025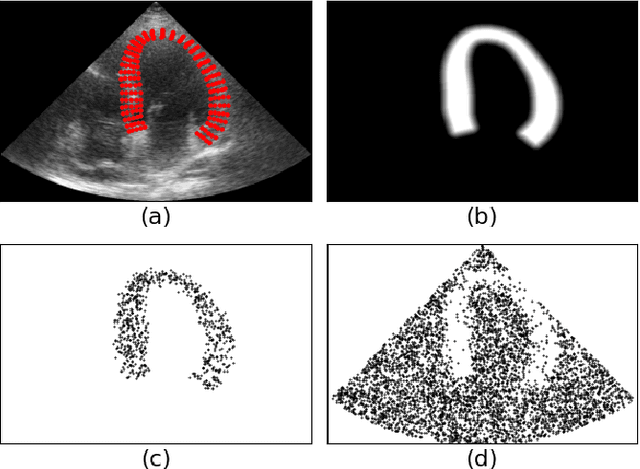
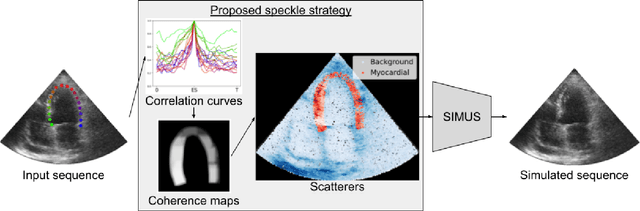
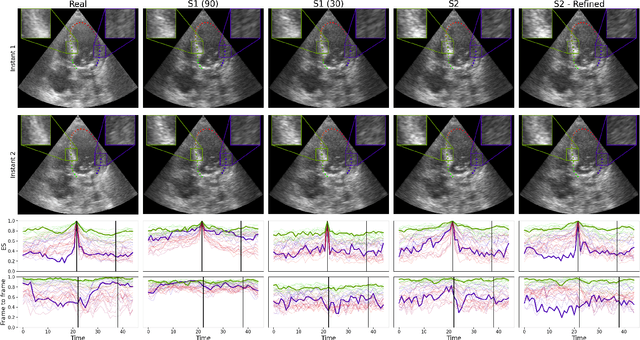
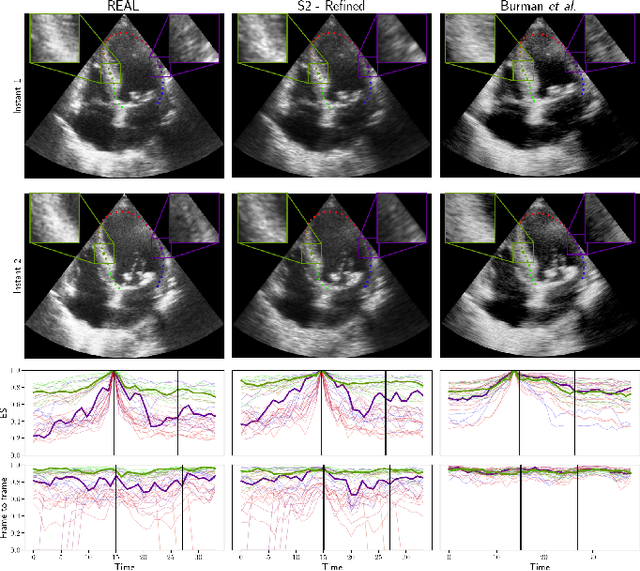
Simulated ultrasound image sequences are key for training and validating machine learning algorithms for left ventricular strain estimation. Several simulation pipelines have been proposed to generate sequences with corresponding ground truth motion, but they suffer from limited realism as they do not consider speckle decorrelation. In this work, we address this limitation by proposing an improved simulation framework that explicitly accounts for speckle decorrelation. Our method builds on an existing ultrasound simulation pipeline by incorporating a dynamic model of speckle variation. Starting from real ultrasound sequences and myocardial segmentations, we generate meshes that guide image formation. Instead of applying a fixed ratio of myocardial and background scatterers, we introduce a coherence map that adapts locally over time. This map is derived from correlation values measured directly from the real ultrasound data, ensuring that simulated sequences capture the characteristic temporal changes observed in practice. We evaluated the realism of our approach using ultrasound data from 98 patients in the CAMUS database. Performance was assessed by comparing correlation curves from real and simulated images. The proposed method achieved lower mean absolute error compared to the baseline pipeline, indicating that it more faithfully reproduces the decorrelation behavior seen in clinical data.
Copula-based mixture model identification for subgroup clustering with imaging applications
Feb 12, 2025
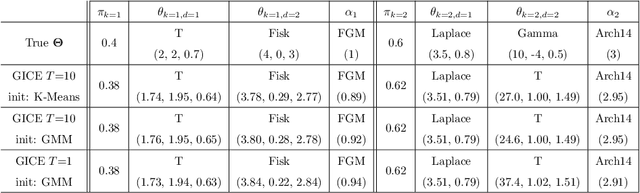

Model-based clustering techniques have been widely applied to various application areas, while most studies focus on canonical mixtures with unique component distribution form. However, this strict assumption is often hard to satisfy. In this paper, we consider the more flexible Copula-Based Mixture Models (CBMMs) for clustering, which allow heterogeneous component distributions composed by flexible choices of marginal and copula forms. More specifically, we propose an adaptation of the Generalized Iterative Conditional Estimation (GICE) algorithm to identify the CBMMs in an unsupervised manner, where the marginal and copula forms and their parameters are estimated iteratively. GICE is adapted from its original version developed for switching Markov model identification with the choice of realization time. Our CBMM-GICE clustering method is then tested on synthetic two-cluster data (N=2000 samples) with discussion of the factors impacting its convergence. Finally, it is compared to the Expectation Maximization identified mixture models with unique component form on the entire MNIST database (N=70000), and on real cardiac magnetic resonance data (N=276) to illustrate its value for imaging applications.
High-dimensional multimodal uncertainty estimation by manifold alignment:Application to 3D right ventricular strain computations
Jan 21, 2025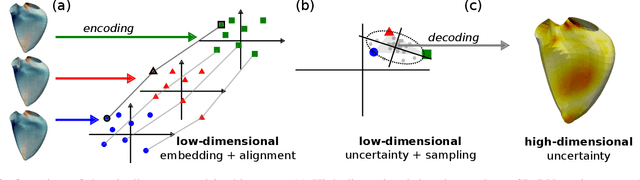
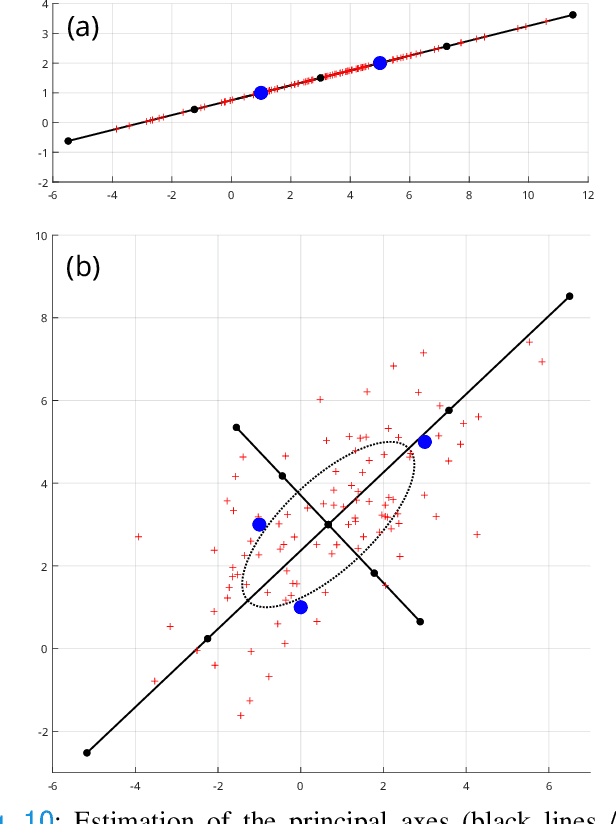
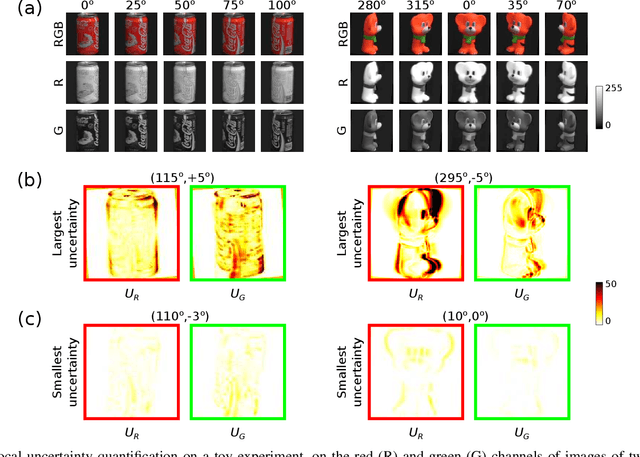
Confidence in the results is a key ingredient to improve the adoption of machine learning methods by clinicians. Uncertainties on the results have been considered in the literature, but mostly those originating from the learning and processing methods. Uncertainty on the data is hardly challenged, as a single sample is often considered representative enough of each subject included in the analysis. In this paper, we propose a representation learning strategy to estimate local uncertainties on a physiological descriptor (here, myocardial deformation) previously obtained from medical images by different definitions or computations. We first use manifold alignment to match the latent representations associated to different high-dimensional input descriptors. Then, we formulate plausible distributions of latent uncertainties, and finally exploit them to reconstruct uncertainties on the input high-dimensional descriptors. We demonstrate its relevance for the quantification of myocardial deformation (strain) from 3D echocardiographic image sequences of the right ventricle, for which a lack of consensus exists in its definition and which directional component to use. We used a database of 100 control subjects with right ventricle overload, for which different types of strain are available at each point of the right ventricle endocardial surface mesh. Our approach quantifies local uncertainties on myocardial deformation from different descriptors defining this physiological concept. Such uncertainties cannot be directly estimated by local statistics on such descriptors, potentially of heterogeneous types. Beyond this controlled illustrative application, our methodology has the potential to be generalized to many other population analyses considering heterogeneous high-dimensional descriptors.
Domain Adaptation of Echocardiography Segmentation Via Reinforcement Learning
Jun 25, 2024



Performance of deep learning segmentation models is significantly challenged in its transferability across different medical imaging domains, particularly when aiming to adapt these models to a target domain with insufficient annotated data for effective fine-tuning. While existing domain adaptation (DA) methods propose strategies to alleviate this problem, these methods do not explicitly incorporate human-verified segmentation priors, compromising the potential of a model to produce anatomically plausible segmentations. We introduce RL4Seg, an innovative reinforcement learning framework that reduces the need to otherwise incorporate large expertly annotated datasets in the target domain, and eliminates the need for lengthy manual human review. Using a target dataset of 10,000 unannotated 2D echocardiographic images, RL4Seg not only outperforms existing state-of-the-art DA methods in accuracy but also achieves 99% anatomical validity on a subset of 220 expert-validated subjects from the target domain. Furthermore, our framework's reward network offers uncertainty estimates comparable with dedicated state-of-the-art uncertainty methods, demonstrating the utility and effectiveness of RL4Seg in overcoming domain adaptation challenges in medical image segmentation.
Fusing Echocardiography Images and Medical Records for Continuous Patient Stratification
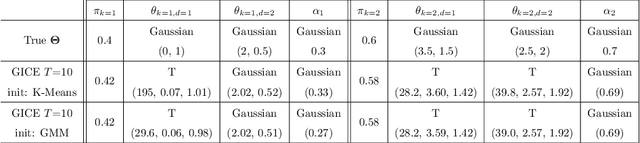
Jan 15, 2024Deep learning now enables automatic and robust extraction of cardiac function descriptors from echocardiographic sequences, such as ejection fraction or strain. These descriptors provide fine-grained information that physicians consider, in conjunction with more global variables from the clinical record, to assess patients' condition. Drawing on novel transformer models applied to tabular data (e.g., variables from electronic health records), we propose a method that considers all descriptors extracted from medical records and echocardiograms to learn the representation of a difficult-to-characterize cardiovascular pathology, namely hypertension. Our method first projects each variable into its own representation space using modality-specific approaches. These standardized representations of multimodal data are then fed to a transformer encoder, which learns to merge them into a comprehensive representation of the patient through a pretext task of predicting a clinical rating. This pretext task is formulated as an ordinal classification to enforce a pathological continuum in the representation space. We observe the major trends along this continuum for a cohort of 239 hypertensive patients to describe, with unprecedented gradation, the effect of hypertension on a number of cardiac function descriptors. Our analysis shows that i) pretrained weights from a foundation model allow to reach good performance (83% accuracy) even with limited data (less than 200 training samples), ii) trends across the population are reproducible between trainings, and iii) for descriptors whose interactions with hypertension are well documented, patterns are consistent with prior physiological knowledge.
Echocardiography Segmentation with Enforced Temporal Consistency
Dec 03, 2021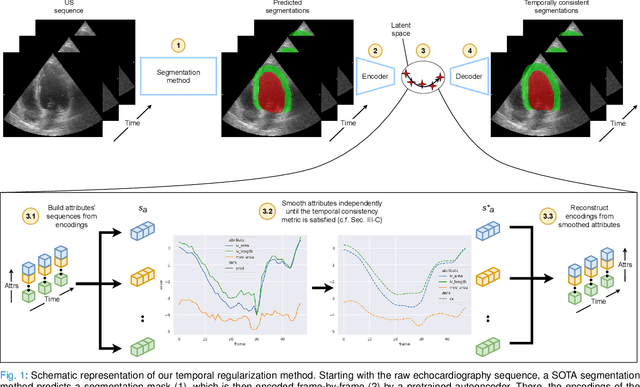
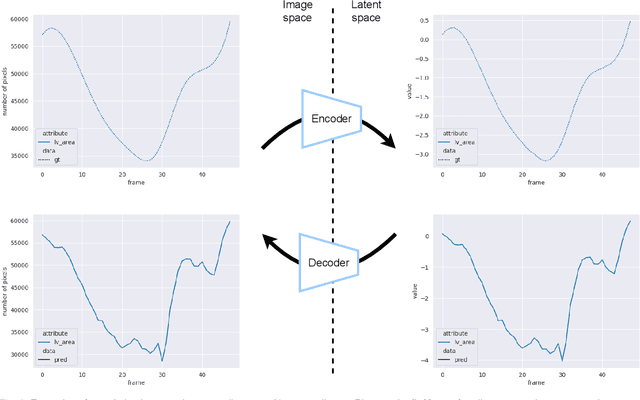

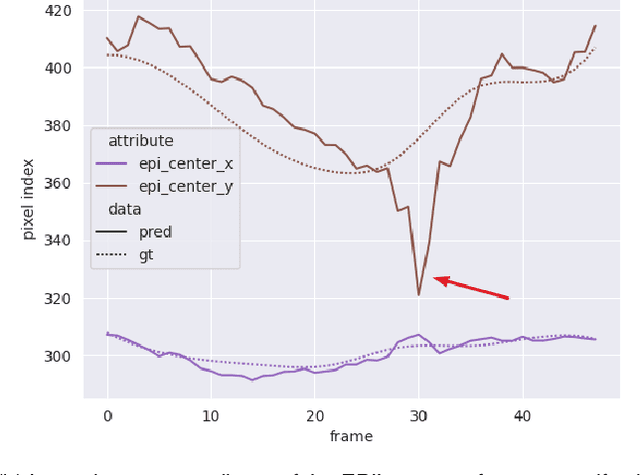
Convolutional neural networks (CNN) have demonstrated their ability to segment 2D cardiac ultrasound images. However, despite recent successes according to which the intra-observer variability on end-diastole and end-systole images has been reached, CNNs still struggle to leverage temporal information to provide accurate and temporally consistent segmentation maps across the whole cycle. Such consistency is required to accurately describe the cardiac function, a necessary step in diagnosing many cardiovascular diseases. In this paper, we propose a framework to learn the 2D+time long-axis cardiac shape such that the segmented sequences can benefit from temporal and anatomical consistency constraints. Our method is a post-processing that takes as input segmented echocardiographic sequences produced by any state-of-the-art method and processes it in two steps to (i) identify spatio-temporal inconsistencies according to the overall dynamics of the cardiac sequence and (ii) correct the inconsistencies. The identification and correction of cardiac inconsistencies relies on a constrained autoencoder trained to learn a physiologically interpretable embedding of cardiac shapes, where we can both detect and fix anomalies. We tested our framework on 98 full-cycle sequences from the CAMUS dataset, which will be rendered public alongside this paper. Our temporal regularization method not only improves the accuracy of the segmentation across the whole sequences, but also enforces temporal and anatomical consistency.
3D Consistent & Robust Segmentation of Cardiac Images by Deep Learning with Spatial Propagation
Apr 25, 2018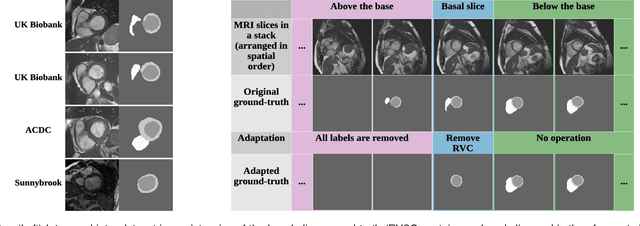
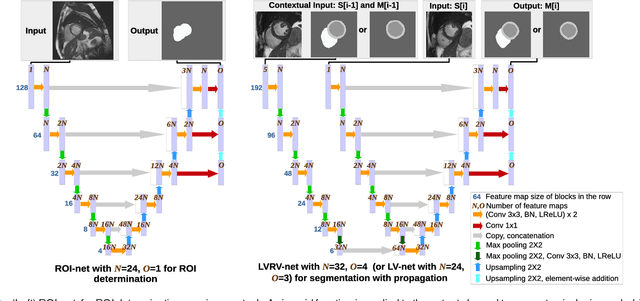
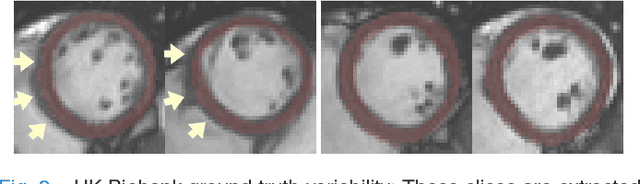
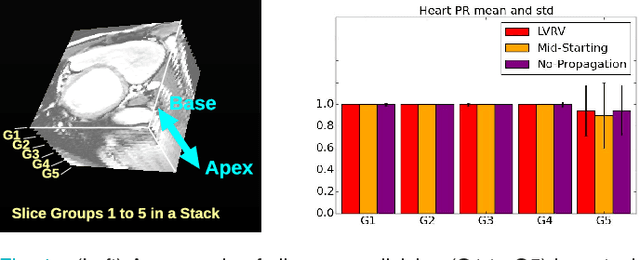
We propose a method based on deep learning to perform cardiac segmentation on short axis MRI image stacks iteratively from the top slice (around the base) to the bottom slice (around the apex). At each iteration, a novel variant of U-net is applied to propagate the segmentation of a slice to the adjacent slice below it. In other words, the prediction of a segmentation of a slice is dependent upon the already existing segmentation of an adjacent slice. 3D-consistency is hence explicitly enforced. The method is trained on a large database of 3078 cases from UK Biobank. It is then tested on 756 different cases from UK Biobank and three other state-of-the-art cohorts (ACDC with 100 cases, Sunnybrook with 30 cases, RVSC with 16 cases). Results comparable or even better than the state-of-the-art in terms of distance measures are achieved. They also emphasize the assets of our method, namely enhanced spatial consistency (currently neither considered nor achieved by the state-of-the-art), and the generalization ability to unseen cases even from other databases.
3D Consistent Biventricular Myocardial Segmentation Using Deep Learning for Mesh Generation
Mar 29, 2018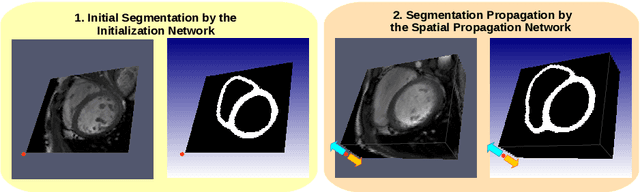
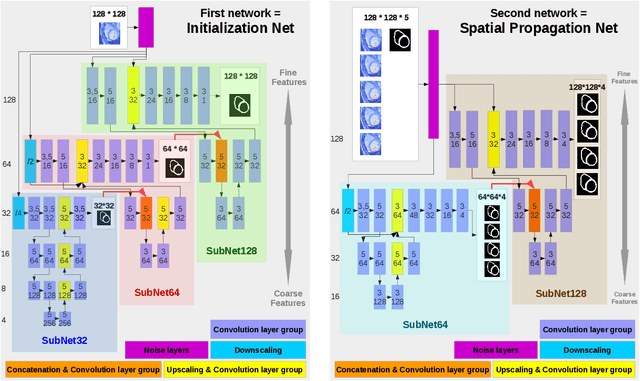
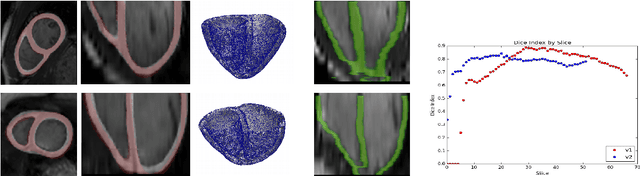
We present a novel automated method to segment the myocardium of both left and right ventricles in MRI volumes. The segmentation is consistent in 3D across the slices such that it can be directly used for mesh generation. Two specific neural networks with multi-scale coarse-to-fine prediction structure are proposed to cope with the small training dataset and trained using an original loss function. The former segments a slice in the middle of the volume. Then the latter iteratively propagates the slice segmentations towards the base and the apex, in a spatially consistent way. We perform 5-fold cross-validation on the 15 cases from STACOM to validate the method. For training, we use real cases and their synthetic variants generated by combining motion simulation and image synthesis. Accurate and consistent testing results are obtained.