Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Private Machine Learning by Differentiable Random Transformations
Paper and Code
Aug 18, 2020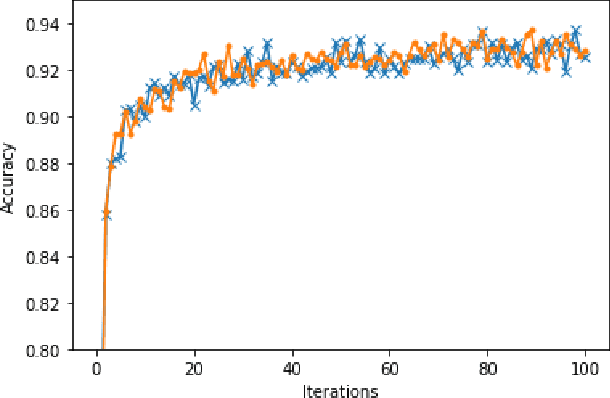
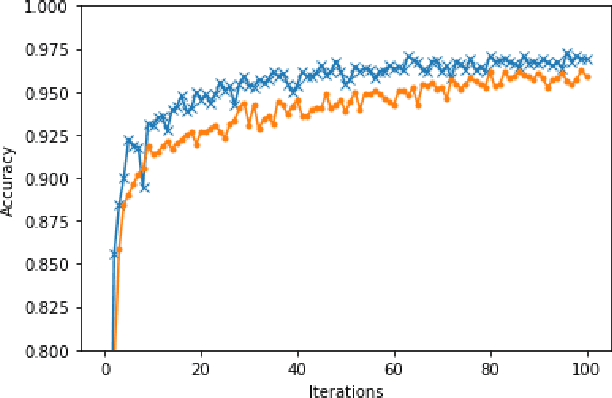

With the increasing demands for privacy protection, many privacy-preserving machine learning systems were proposed in recent years. However, most of them cannot be put into production due to their slow training and inference speed caused by the heavy cost of homomorphic encryption and secure multiparty computation(MPC) methods. To circumvent this, I proposed a privacy definition which is suitable for large amount of data in machine learning tasks. Based on that, I showed that random transformations like linear transformation and random permutation can well protect privacy. Merging random transformations and arithmetic sharing together, I designed a framework for private machine learning with high efficiency and low computation cost.
View paper on