 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Feb 04, 2026Monocular video human mesh recovery faces fundamental challenges in maintaining metric consistency and temporal stability due to inherent depth ambiguities and scale uncertainties. While existing methods rely primarily on RGB features and temporal smoothing, they struggle with depth ordering, scale drift, and occlusion-induced instabilities. We propose a comprehensive depth-guided framework that achieves metric-aware temporal consistency through three synergistic components: A Depth-Guided Multi-Scale Fusion module that adaptively integrates geometric priors with RGB features via confidence-aware gating; A Depth-guided Metric-Aware Pose and Shape (D-MAPS) estimator that leverages depth-calibrated bone statistics for scale-consistent initialization; A Motion-Depth Aligned Refinement (MoDAR) module that enforces temporal coherence through cross-modal attention between motion dynamics and geometric cues. Our method achieves superior results on three challenging benchmarks, demonstrating significant improvements in robustness against heavy occlusion and spatial accuracy while maintaining computational efficiency.
MorphText: Deep Morphology Regularized Arbitrary-shape Scene Text Detection
Apr 26, 2024

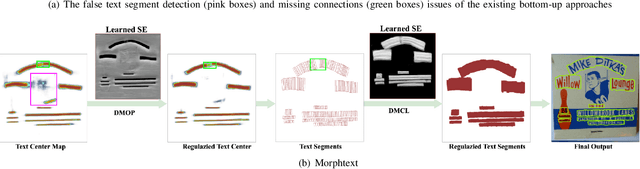
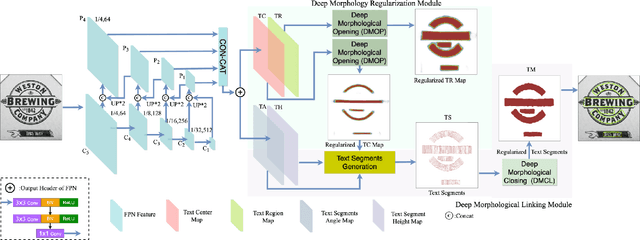
Bottom-up text detection methods play an important role in arbitrary-shape scene text detection but there are two restrictions preventing them from achieving their great potential, i.e., 1) the accumulation of false text segment detections, which affects subsequent processing, and 2) the difficulty of building reliable connections between text segments. Targeting these two problems, we propose a novel approach, named ``MorphText", to capture the regularity of texts by embedding deep morphology for arbitrary-shape text detection. Towards this end, two deep morphological modules are designed to regularize text segments and determine the linkage between them. First, a Deep Morphological Opening (DMOP) module is constructed to remove false text segment detections generated in the feature extraction process. Then, a Deep Morphological Closing (DMCL) module is proposed to allow text instances of various shapes to stretch their morphology along their most significant orientation while deriving their connections. Extensive experiments conducted on four challenging benchmark datasets (CTW1500, Total-Text, MSRA-TD500 and ICDAR2017) demonstrate that our proposed MorphText outperforms both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches.
SFSegNet: Parse Freehand Sketches using Deep Fully Convolutional Networks
Aug 15, 2019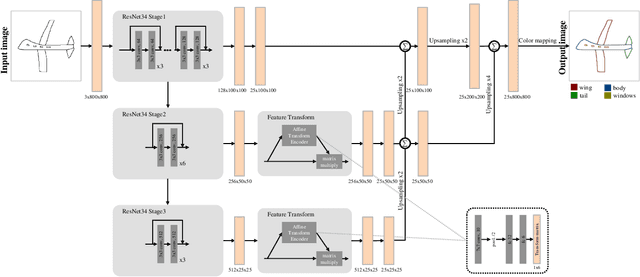
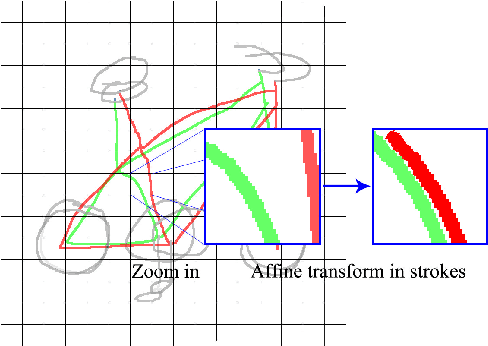
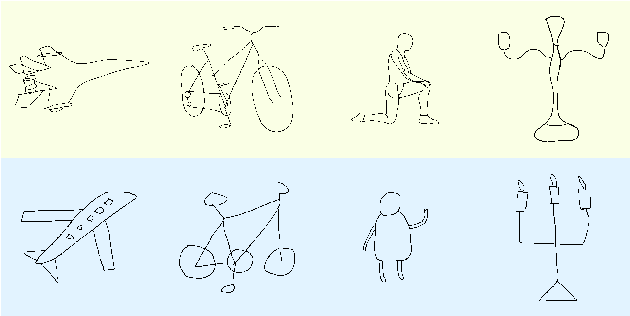
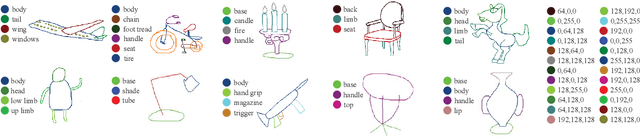
Parsing sketches via semantic segmentation is attractive but challenging, because (i) free-hand drawings are abstract with large variances in depicting objects due to different drawing styles and skills; (ii) distorting lines drawn on the touchpad make sketches more difficult to be recognized; (iii) the high-performance image segmentation via deep learning technologies needs enormous annotated sketch datasets during the training stage. In this paper, we propose a Sketch-target deep FCN Segmentation Network(SFSegNet) for automatic free-hand sketch segmentation, labeling each sketch in a single object with multiple parts. SFSegNet has an end-to-end network process between the input sketches and the segmentation results, composed of 2 parts: (i) a modified deep Fully Convolutional Network(FCN) using a reweighting strategy to ignore background pixels and classify which part each pixel belongs to; (ii) affine transform encoders that attempt to canonicalize the shaking strokes. We train our network with the dataset that consists of 10,000 annotated sketches, to find an extensively applicable model to segment stokes semantically in one ground truth. Extensive experiments are carried out and segmentation results show that our method outperforms other state-of-the-art networks.
Structured Inhomogeneous Density Map Learning for Crowd Counting
Jan 20, 2018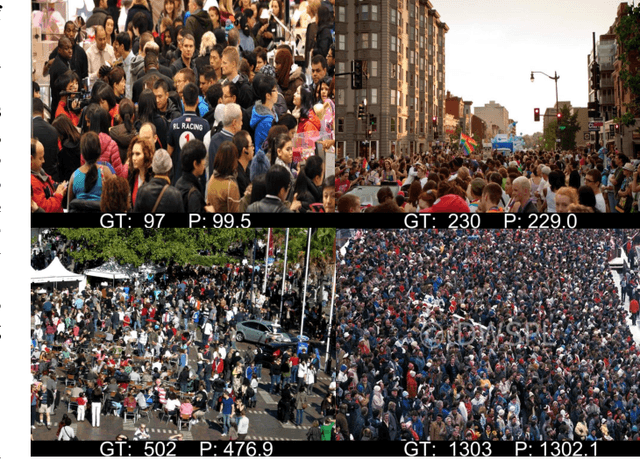
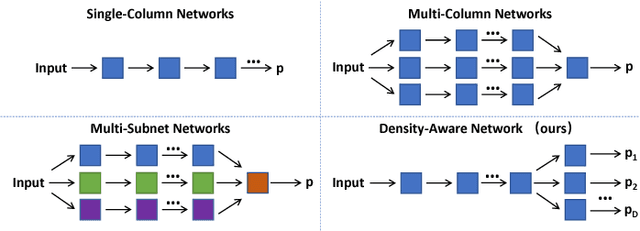

In this paper, we aim at tackling the problem of crowd counting in extremely high-density scenes, which contain hundreds, or even thousands of people. We begin by a comprehensive analysis of the most widely used density map-based methods, and demonstrate how easily existing methods are affected by the inhomogeneous density distribution problem, e.g., causing them to be sensitive to outliers, or be hard to optimized. We then present an extremely simple solution to the inhomogeneous density distribution problem, which can be intuitively summarized as extending the density map from 2D to 3D, with the extra dimension implicitly indicating the density level. Such solution can be implemented by a single Density-Aware Network, which is not only easy to train, but also can achieve the state-of-art performance on various challenging datasets.
Learning Deep Similarity Models with Focus Ranking for Fabric Image Retrieval
Dec 29, 2017

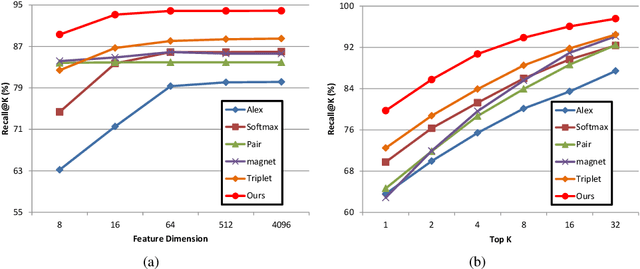
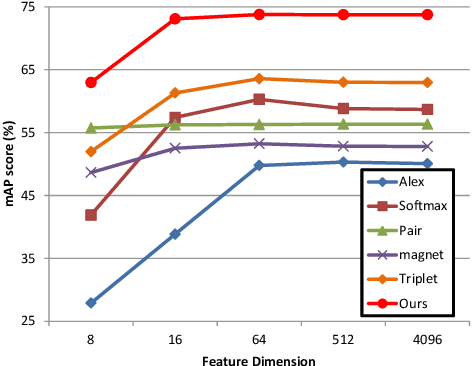
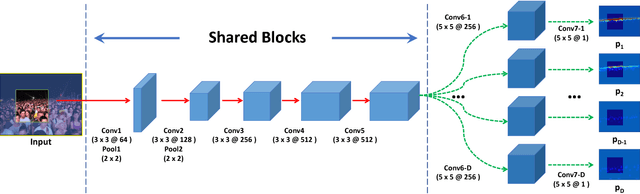
Fabric image retrieval is beneficial to many applications including clothing searching, online shopping and cloth modeling. Learning pairwise image similarity is of great importance to an image retrieval task. With the resurgence of Convolutional Neural Networks (CNNs), recent works have achieved significant progresses via deep representation learning with metric embedding, which drives similar examples close to each other in a feature space, and dissimilar ones apart from each other. In this paper, we propose a novel embedding method termed focus ranking that can be easily unified into a CNN for jointly learning image representations and metrics in the context of fine-grained fabric image retrieval. Focus ranking aims to rank similar examples higher than all dissimilar ones by penalizing ranking disorders via the minimization of the overall cost attributed to similar samples being ranked below dissimilar ones. At the training stage, training samples are organized into focus ranking units for efficient optimization. We build a large-scale fabric image retrieval dataset (FIRD) with about 25,000 images of 4,300 fabrics, and test the proposed model on the FIRD dataset. Experimental results show the superiority of the proposed model over existing metric embedding models.