 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMoGen: Language to Motion Generation Through LLM-Guided Symbolic Inference
Mar 12, 2026Human motion is highly expressive and naturally aligned with language, yet prevailing methods relying heavily on joint text-motion embeddings struggle to synthesize temporally accurate, detailed motions and often lack explainability. To address these limitations, we introduce LabanLite, a motion representation developed by adapting and extending the Labanotation system. Unlike black-box text-motion embeddings, LabanLite encodes each atomic body-part action (e.g., a single left-foot step) as a discrete Laban symbol paired with a textual template. This abstraction decomposes complex motions into interpretable symbol sequences and body-part instructions, establishing a symbolic link between high-level language and low-level motion trajectories. Building on LabanLite, we present LaMoGen, a Text-to-LabanLite-to-Motion Generation framework that enables large language models (LLMs) to compose motion sequences through symbolic reasoning. The LLM interprets motion patterns, relates them to textual descriptions, and recombines symbols into executable plans, producing motions that are both interpretable and linguistically grounded. To support rigorous evaluation, we introduce a Labanotation-based benchmark with structured description-motion pairs and three metrics that jointly measure text-motion alignment across symbolic, temporal, and harmony dimensions. Experiments demonstrate that LaMoGen establishes a new baseline for both interpretability and controllability, outperforming prior methods on our benchmark and two public datasets. These results highlight the advantages of symbolic reasoning and agent-based design for language-driven motion synthesis.
Learning Context-Adaptive Motion Priors for Masked Motion Diffusion Models with Efficient Kinematic Attention Aggregation
Mar 08, 2026Vision-based motion capture solutions often struggle with occlusions, which result in the loss of critical joint information and hinder accurate 3D motion reconstruction. Other wearable alternatives also suffer from noisy or unstable data, often requiring extensive manual cleaning and correction to achieve reliable results. To address these challenges, we introduce the Masked Motion Diffusion Model (MMDM), a diffusion-based generative reconstruction framework that enhances incomplete or low-confidence motion data using partially available high-quality reconstructions within a Masked Autoencoder architecture. Central to our design is the Kinematic Attention Aggregation (KAA) mechanism, which enables efficient, deep, and iterative encoding of both joint-level and pose-level features, capturing structural and temporal motion patterns essential for task-specific reconstruction. We focus on learning context-adaptive motion priors, specialized structural and temporal features extracted by the same reusable architecture, where each learned prior emphasizes different aspects of motion dynamics and is specifically efficient for its corresponding task. This enables the architecture to adaptively specialize without altering its structure. Such versatility allows MMDM to efficiently learn motion priors tailored to scenarios such as motion refinement, completion, and in-betweening. Extensive evaluations on public benchmarks demonstrate that MMDM achieves strong performance across diverse masking strategies and task settings. The source code is available at https://github.com/jjkislele/MMDM.
Deep Compositional Phase Diffusion for Long Motion Sequence Generation
Oct 16, 2025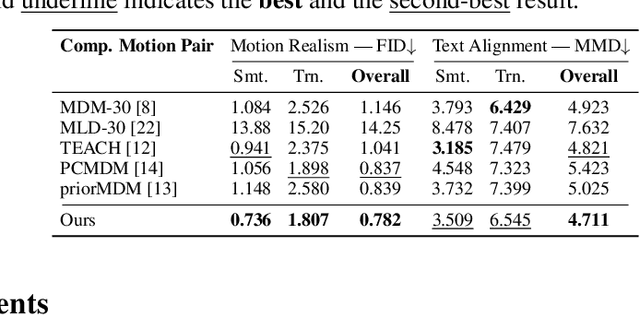
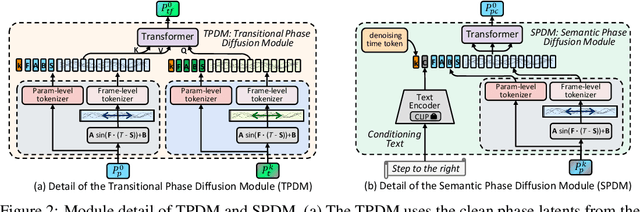
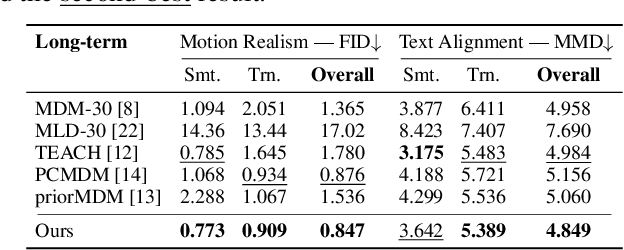
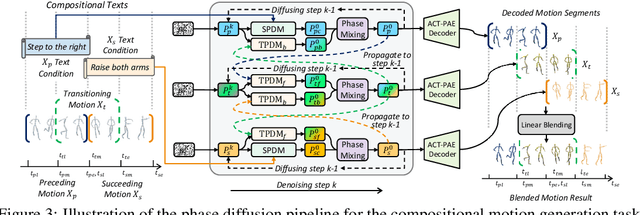
Recent research on motion generation has shown significant progress in generating semantically aligned motion with singular semantics. However, when employing these models to create composite sequences containing multiple semantically generated motion clips, they often struggle to preserve the continuity of motion dynamics at the transition boundaries between clips, resulting in awkward transitions and abrupt artifacts. To address these challenges, we present Compositional Phase Diffusion, which leverages the Semantic Phase Diffusion Module (SPDM) and Transitional Phase Diffusion Module (TPDM) to progressively incorporate semantic guidance and phase details from adjacent motion clips into the diffusion process. Specifically, SPDM and TPDM operate within the latent motion frequency domain established by the pre-trained Action-Centric Motion Phase Autoencoder (ACT-PAE). This allows them to learn semantically important and transition-aware phase information from variable-length motion clips during training. Experimental results demonstrate the competitive performance of our proposed framework in generating compositional motion sequences that align semantically with the input conditions, while preserving phase transitional continuity between preceding and succeeding motion clips. Additionally, motion inbetweening task is made possible by keeping the phase parameter of the input motion sequences fixed throughout the diffusion process, showcasing the potential for extending the proposed framework to accommodate various application scenarios. Codes are available at https://github.com/asdryau/TransPhase.
Every Angle Is Worth A Second Glance: Mining Kinematic Skeletal Structures from Multi-view Joint Cloud
Feb 05, 2025
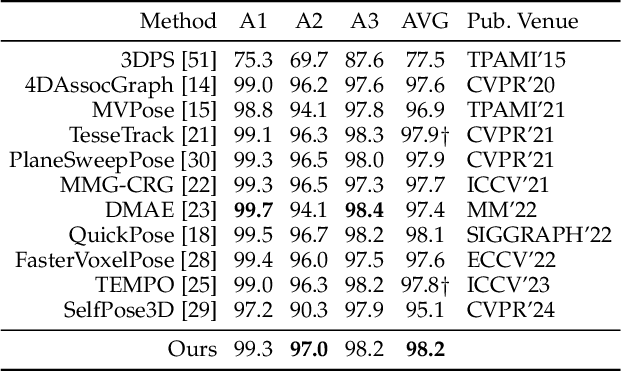

Multi-person motion capture over sparse angular observations is a challenging problem under interference from both self- and mutual-occlusions. Existing works produce accurate 2D joint detection, however, when these are triangulated and lifted into 3D, available solutions all struggle in selecting the most accurate candidates and associating them to the correct joint type and target identity. As such, in order to fully utilize all accurate 2D joint location information, we propose to independently triangulate between all same-typed 2D joints from all camera views regardless of their target ID, forming the Joint Cloud. Joint Cloud consist of both valid joints lifted from the same joint type and target ID, as well as falsely constructed ones that are from different 2D sources. These redundant and inaccurate candidates are processed over the proposed Joint Cloud Selection and Aggregation Transformer (JCSAT) involving three cascaded encoders which deeply explore the trajectile, skeletal structural, and view-dependent correlations among all 3D point candidates in the cross-embedding space. An Optimal Token Attention Path (OTAP) module is proposed which subsequently selects and aggregates informative features from these redundant observations for the final prediction of human motion. To demonstrate the effectiveness of JCSAT, we build and publish a new multi-person motion capture dataset BUMocap-X with complex interactions and severe occlusions. Comprehensive experiments over the newly presented as well as benchmark datasets validate the effectiveness of the proposed framework, which outperforms all existing state-of-the-art methods, especially under challenging occlusion scenarios.
Exploring Latent Cross-Channel Embedding for Accurate 3D Human Pose Reconstruction in a Diffusion Framework
Jan 18, 2024Monocular 3D human pose estimation poses significant challenges due to the inherent depth ambiguities that arise during the reprojection process from 2D to 3D. Conventional approaches that rely on estimating an over-fit projection matrix struggle to effectively address these challenges and often result in noisy outputs. Recent advancements in diffusion models have shown promise in incorporating structural priors to address reprojection ambiguities. However, there is still ample room for improvement as these methods often overlook the exploration of correlation between the 2D and 3D joint-level features. In this study, we propose a novel cross-channel embedding framework that aims to fully explore the correlation between joint-level features of 3D coordinates and their 2D projections. In addition, we introduce a context guidance mechanism to facilitate the propagation of joint graph attention across latent channels during the iterative diffusion process. To evaluate the effectiveness of our proposed method, we conduct experiments on two benchmark datasets, namely Human3.6M and MPI-INF-3DHP. Our results demonstrate a significant improvement in terms of reconstruction accuracy compared to state-of-the-art methods. The code for our method will be made available online for further reference.
A Dual-Masked Auto-Encoder for Robust Motion Capture with Spatial-Temporal Skeletal Token Completion
Jul 15, 2022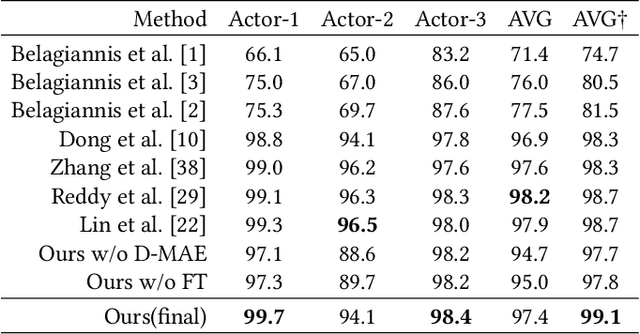
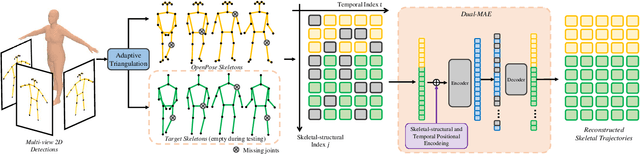

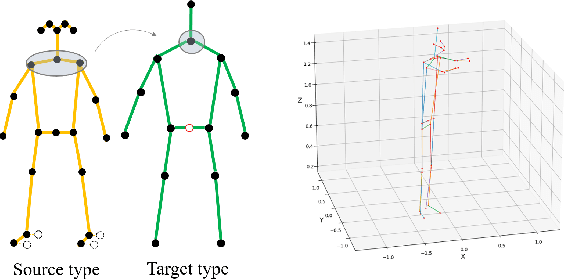
Multi-person motion capture can be challenging due to ambiguities caused by severe occlusion, fast body movement, and complex interactions. Existing frameworks build on 2D pose estimations and triangulate to 3D coordinates via reasoning the appearance, trajectory, and geometric consistencies among multi-camera observations. However, 2D joint detection is usually incomplete and with wrong identity assignments due to limited observation angle, which leads to noisy 3D triangulation results. To overcome this issue, we propose to explore the short-range autoregressive characteristics of skeletal motion using transformer. First, we propose an adaptive, identity-aware triangulation module to reconstruct 3D joints and identify the missing joints for each identity. To generate complete 3D skeletal motion, we then propose a Dual-Masked Auto-Encoder (D-MAE) which encodes the joint status with both skeletal-structural and temporal position encoding for trajectory completion. D-MAE's flexible masking and encoding mechanism enable arbitrary skeleton definitions to be conveniently deployed under the same framework. In order to demonstrate the proposed model's capability in dealing with severe data loss scenarios, we contribute a high-accuracy and challenging motion capture dataset of multi-person interactions with severe occlusion. Evaluations on both benchmark and our new dataset demonstrate the efficiency of our proposed model, as well as its advantage against the other state-of-the-art methods.
SFSegNet: Parse Freehand Sketches using Deep Fully Convolutional Networks
Aug 15, 2019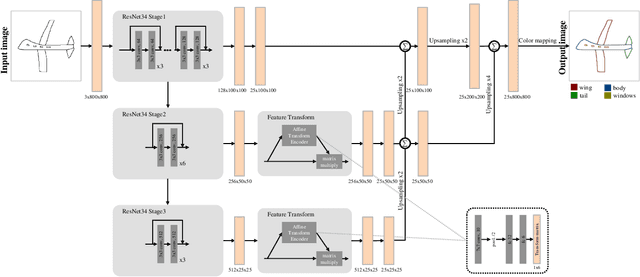
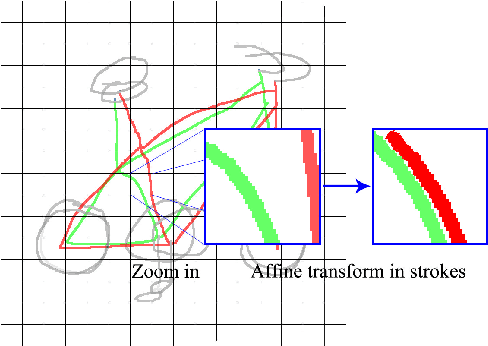
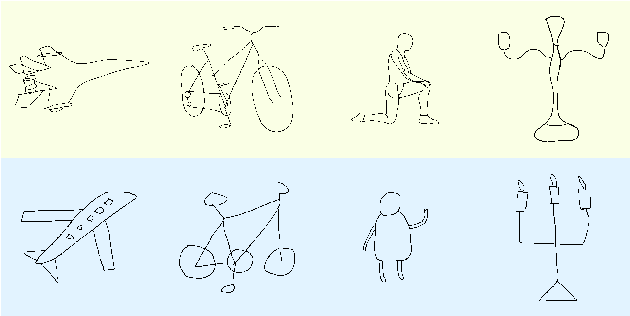
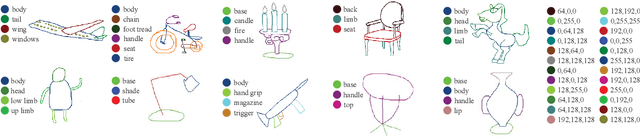
Parsing sketches via semantic segmentation is attractive but challenging, because (i) free-hand drawings are abstract with large variances in depicting objects due to different drawing styles and skills; (ii) distorting lines drawn on the touchpad make sketches more difficult to be recognized; (iii) the high-performance image segmentation via deep learning technologies needs enormous annotated sketch datasets during the training stage. In this paper, we propose a Sketch-target deep FCN Segmentation Network(SFSegNet) for automatic free-hand sketch segmentation, labeling each sketch in a single object with multiple parts. SFSegNet has an end-to-end network process between the input sketches and the segmentation results, composed of 2 parts: (i) a modified deep Fully Convolutional Network(FCN) using a reweighting strategy to ignore background pixels and classify which part each pixel belongs to; (ii) affine transform encoders that attempt to canonicalize the shaking strokes. We train our network with the dataset that consists of 10,000 annotated sketches, to find an extensively applicable model to segment stokes semantically in one ground truth. Extensive experiments are carried out and segmentation results show that our method outperforms other state-of-the-art networks.