Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Dialogue State Tracking with Temporally Expressive Networks
Paper and Code
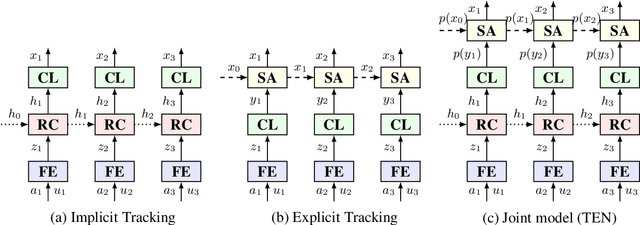
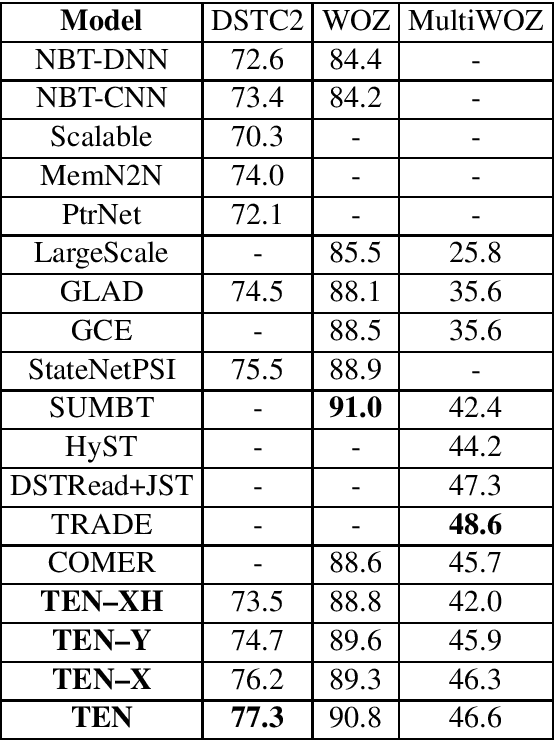
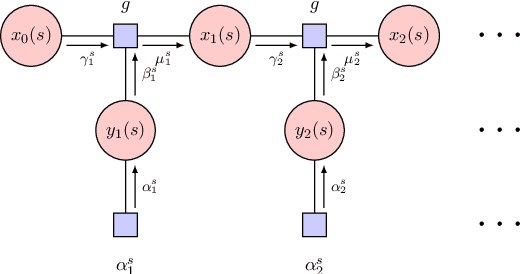
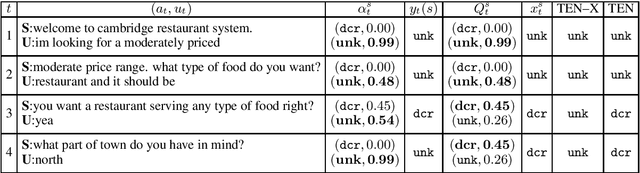
Dialogue state tracking (DST) is an important part of a spoken dialogue system. Existing DST models either ignore temporal feature dependencies across dialogue turns or fail to explicitly model temporal state dependencies in a dialogue. In this work, we propose Temporally Expressive Networks (TEN) to jointly model the two types of temporal dependencies in DST. The TEN model utilizes the power of recurrent networks and probabilistic graphical models. Evaluating on standard datasets, TEN is demonstrated to be effective in improving the accuracy of turn-level-state prediction and the state aggregation.
* Accepted by Findings of EMNLP 2020
View paper on