 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Classification with Decoupled Representation
Paper and Code
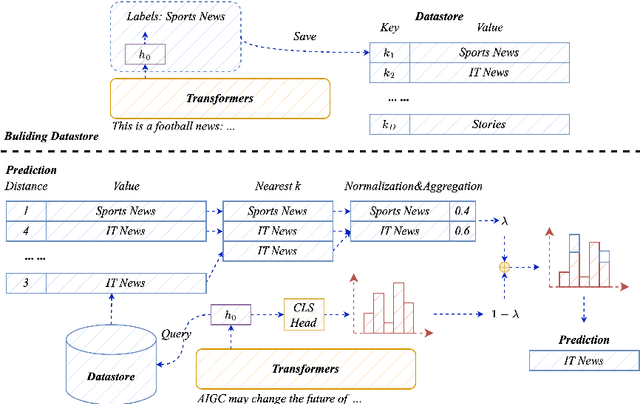

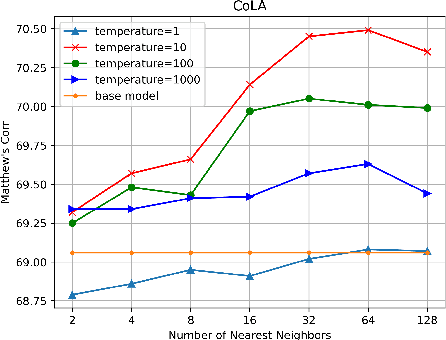

Pretrained language models (PLMs) have shown marvelous improvements across various NLP tasks. Most Chinese PLMs simply treat an input text as a sequence of characters, and completely ignore word information. Although Whole Word Masking can alleviate this, the semantics in words is still not well represented. In this paper, we revisit the segmentation granularity of Chinese PLMs. We propose a mixed-granularity Chinese BERT (MigBERT) by considering both characters and words. To achieve this, we design objective functions for learning both character and word-level representations. We conduct extensive experiments on various Chinese NLP tasks to evaluate existing PLMs as well as the proposed MigBERT. Experimental results show that MigBERT achieves new SOTA performance on all these tasks. Further analysis demonstrates that words are semantically richer than characters. More interestingly, we show that MigBERT also works with Japanese. Our code has been released here~\footnote{\url{https://github.com/xnliang98/MigBERT}} and you can download our model here~\footnote{\url{https://huggingface.co/xnliang/MigBERT-large/}}.