 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Role of Explicit Temporal Modeling in Multimodal Large Language Models for Video Understanding
Jan 28, 2025
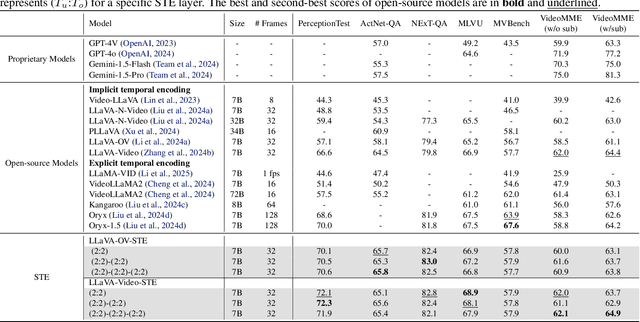
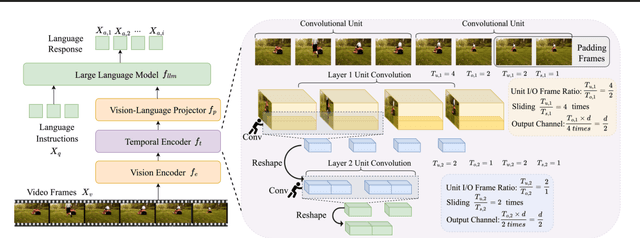
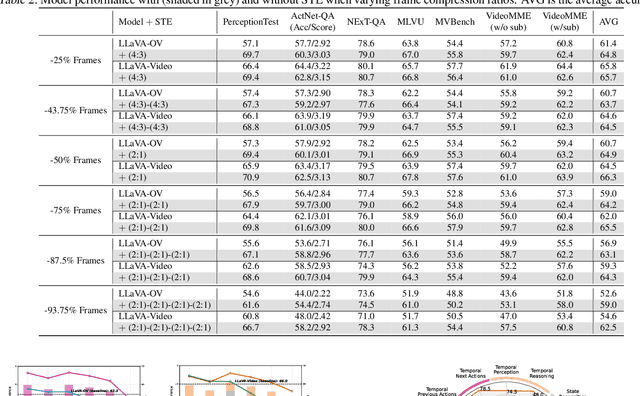
Applying Multimodal Large Language Models (MLLMs) to video understanding presents significant challenges due to the need to model temporal relations across frames. Existing approaches adopt either implicit temporal modeling, relying solely on the LLM decoder, or explicit temporal modeling, employing auxiliary temporal encoders. To investigate this debate between the two paradigms, we propose the Stackable Temporal Encoder (STE). STE enables flexible explicit temporal modeling with adjustable temporal receptive fields and token compression ratios. Using STE, we systematically compare implicit and explicit temporal modeling across dimensions such as overall performance, token compression effectiveness, and temporal-specific understanding. We also explore STE's design considerations and broader impacts as a plug-in module and in image modalities. Our findings emphasize the critical role of explicit temporal modeling, providing actionable insights to advance video MLLMs.
Balancing Stability and Plasticity through Advanced Null Space in Continual Learning
Jul 25, 2022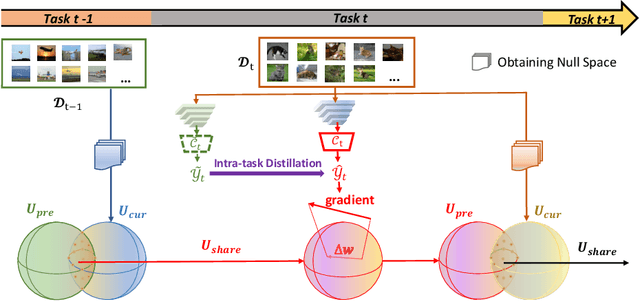
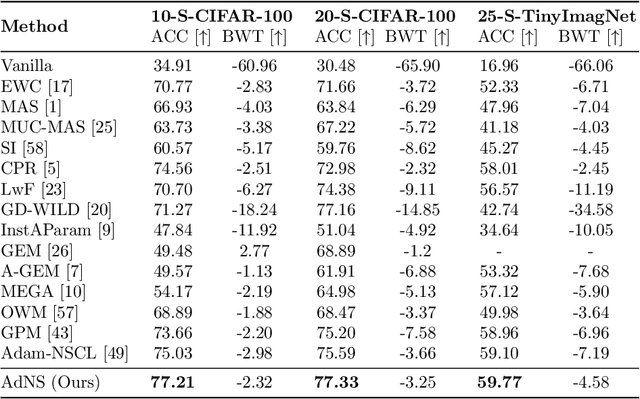
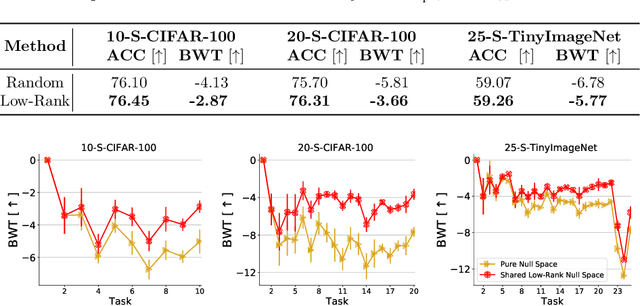
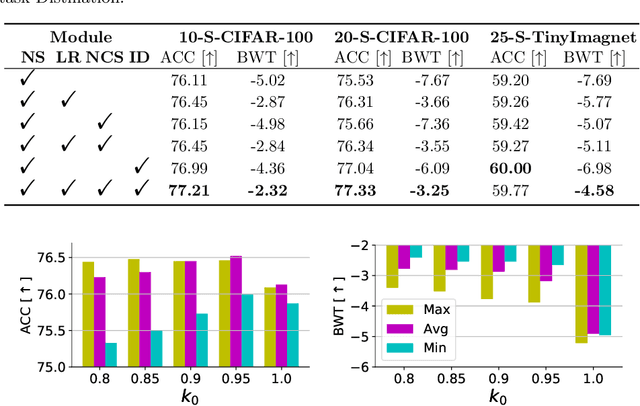
Continual learning is a learning paradigm that learns tasks sequentially with resources constraints, in which the key challenge is stability-plasticity dilemma, i.e., it is uneasy to simultaneously have the stability to prevent catastrophic forgetting of old tasks and the plasticity to learn new tasks well. In this paper, we propose a new continual learning approach, Advanced Null Space (AdNS), to balance the stability and plasticity without storing any old data of previous tasks. Specifically, to obtain better stability, AdNS makes use of low-rank approximation to obtain a novel null space and projects the gradient onto the null space to prevent the interference on the past tasks. To control the generation of the null space, we introduce a non-uniform constraint strength to further reduce forgetting. Furthermore, we present a simple but effective method, intra-task distillation, to improve the performance of the current task. Finally, we theoretically find that null space plays a key role in plasticity and stability, respectively. Experimental results show that the proposed method can achieve better performance compared to state-of-the-art continual learning approaches.
Online Continual Learning with Contrastive Vision Transformer
Jul 24, 2022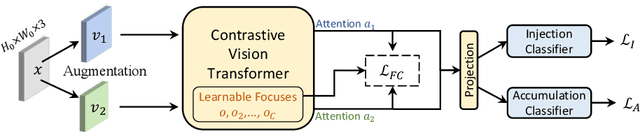
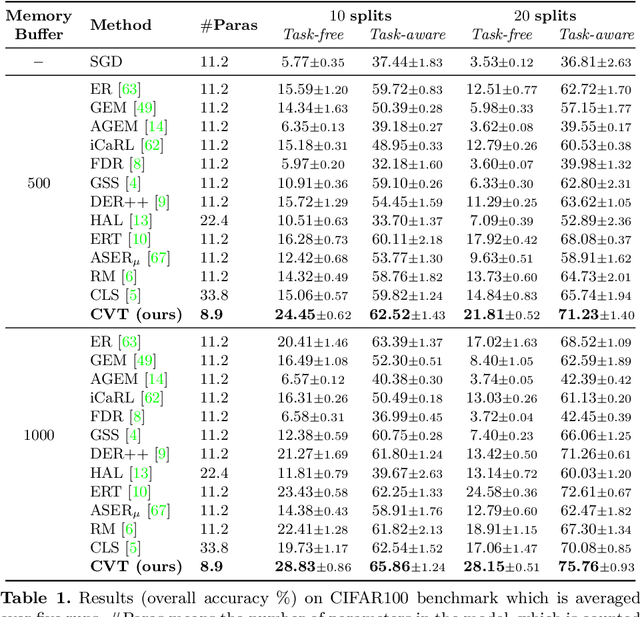
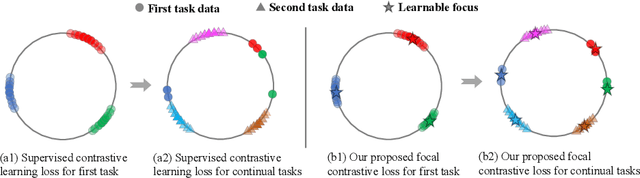
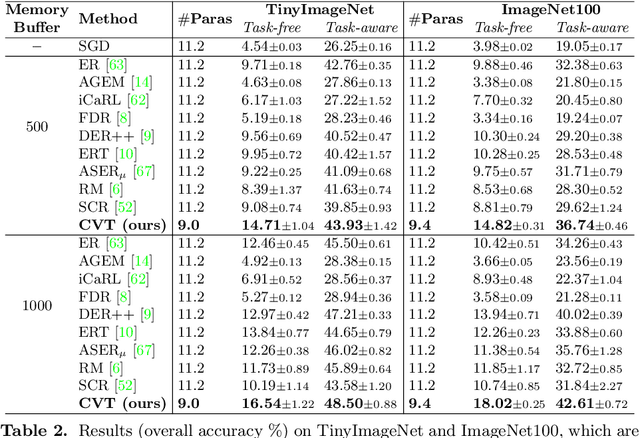
Online continual learning (online CL) studies the problem of learning sequential tasks from an online data stream without task boundaries, aiming to adapt to new data while alleviating catastrophic forgetting on the past tasks. This paper proposes a framework Contrastive Vision Transformer (CVT), which designs a focal contrastive learning strategy based on a transformer architecture, to achieve a better stability-plasticity trade-off for online CL. Specifically, we design a new external attention mechanism for online CL that implicitly captures previous tasks' information. Besides, CVT contains learnable focuses for each class, which could accumulate the knowledge of previous classes to alleviate forgetting. Based on the learnable focuses, we design a focal contrastive loss to rebalance contrastive learning between new and past classes and consolidate previously learned representations. Moreover, CVT contains a dual-classifier structure for decoupling learning current classes and balancing all observed classes. The extensive experimental results show that our approach achieves state-of-the-art performance with even fewer parameters on online CL benchmarks and effectively alleviates the catastrophic forgetting.