 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Bioinformatics
Jan 10, 2025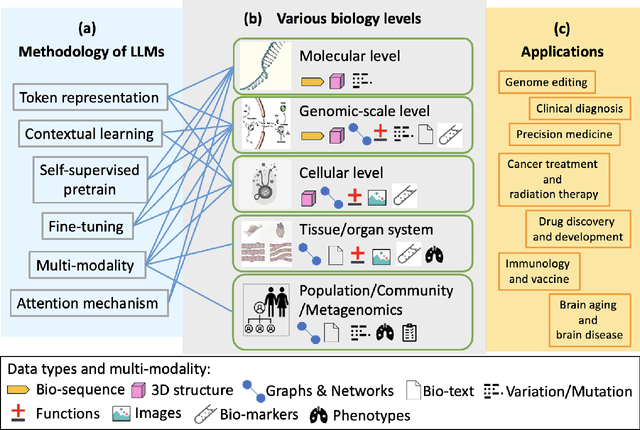
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Towards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios
Nov 16, 2024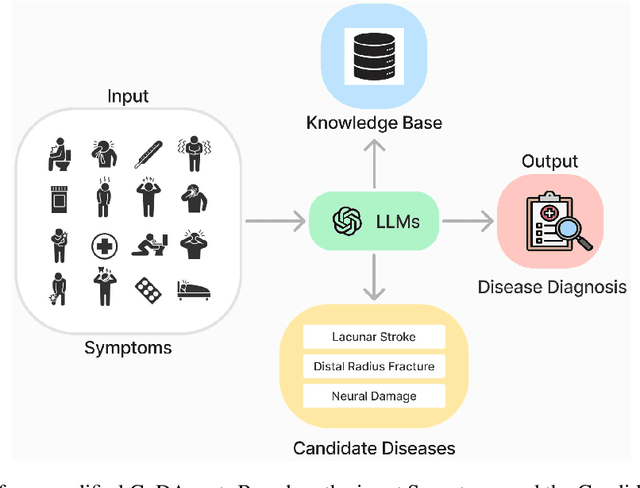

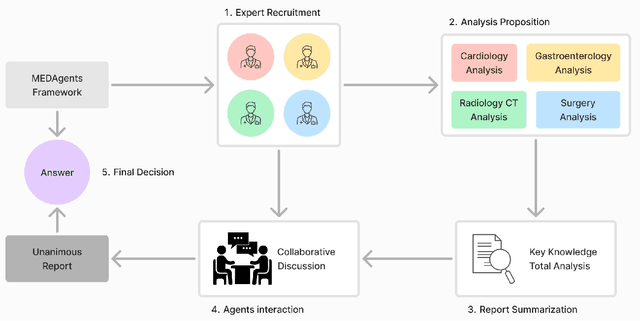

Artificial Intelligence (AI) has become essential in modern healthcare, with large language models (LLMs) offering promising advances in clinical decision-making. Traditional model-based approaches, including those leveraging in-context demonstrations and those with specialized medical fine-tuning, have demonstrated strong performance in medical language processing but struggle with real-time adaptability, multi-step reasoning, and handling complex medical tasks. Agent-based AI systems address these limitations by incorporating reasoning traces, tool selection based on context, knowledge retrieval, and both short- and long-term memory. These additional features enable the medical AI agent to handle complex medical scenarios where decision-making should be built on real-time interaction with the environment. Therefore, unlike conventional model-based approaches that treat medical queries as isolated questions, medical AI agents approach them as complex tasks and behave more like human doctors. In this paper, we study the choice of the backbone LLM for medical AI agents, which is the foundation for the agent's overall reasoning and action generation. In particular, we consider the emergent o1 model and examine its impact on agents' reasoning, tool-use adaptability, and real-time information retrieval across diverse clinical scenarios, including high-stakes settings such as intensive care units (ICUs). Our findings demonstrate o1's ability to enhance diagnostic accuracy and consistency, paving the way for smarter, more responsive AI tools that support better patient outcomes and decision-making efficacy in clinical practice.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024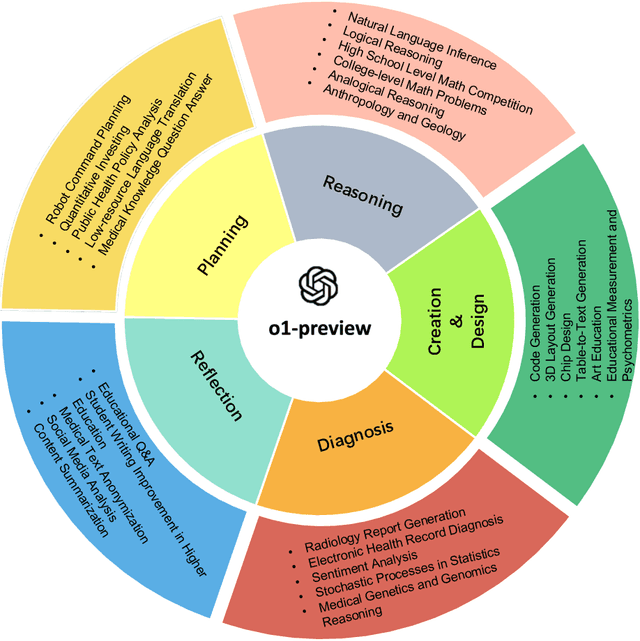

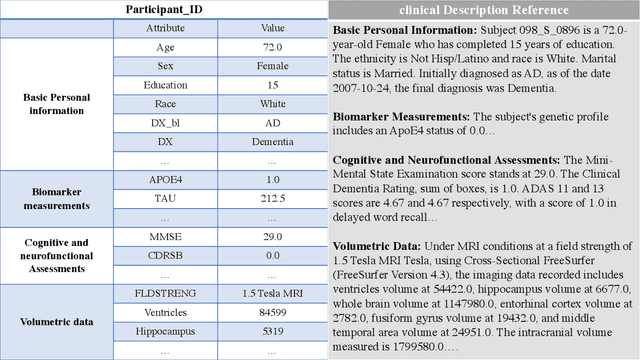

This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
Feb 20, 2024



In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
PharmacyGPT: The AI Pharmacist
Jul 21, 2023In this study, we introduce PharmacyGPT, a novel framework to assess the capabilities of large language models (LLMs) such as ChatGPT and GPT-4 in emulating the role of clinical pharmacists. Our methodology encompasses the utilization of LLMs to generate comprehensible patient clusters, formulate medication plans, and forecast patient outcomes. We conduct our investigation using real data acquired from the intensive care unit (ICU) at the University of North Carolina Chapel Hill (UNC) Hospital. Our analysis offers valuable insights into the potential applications and limitations of LLMs in the field of clinical pharmacy, with implications for both patient care and the development of future AI-driven healthcare solutions. By evaluating the performance of PharmacyGPT, we aim to contribute to the ongoing discourse surrounding the integration of artificial intelligence in healthcare settings, ultimately promoting the responsible and efficacious use of such technologies.