 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema-Aware Multi-Task Learning for Complex Text-to-SQL
Mar 09, 2024



Conventional text-to-SQL parsers are not good at synthesizing complex SQL queries that involve multiple tables or columns, due to the challenges inherent in identifying the correct schema items and performing accurate alignment between question and schema items. To address the above issue, we present a schema-aware multi-task learning framework (named MTSQL) for complicated SQL queries. Specifically, we design a schema linking discriminator module to distinguish the valid question-schema linkings, which explicitly instructs the encoder by distinctive linking relations to enhance the alignment quality. On the decoder side, we define 6-type relationships to describe the connections between tables and columns (e.g., WHERE_TC), and introduce an operator-centric triple extractor to recognize those associated schema items with the predefined relationship. Also, we establish a rule set of grammar constraints via the predicted triples to filter the proper SQL operators and schema items during the SQL generation. On Spider, a cross-domain challenging text-to-SQL benchmark, experimental results indicate that MTSQL is more effective than baselines, especially in extremely hard scenarios. Moreover, further analyses verify that our approach leads to promising improvements for complicated SQL queries.
TLM: Token-Level Masking for Transformers
Oct 28, 2023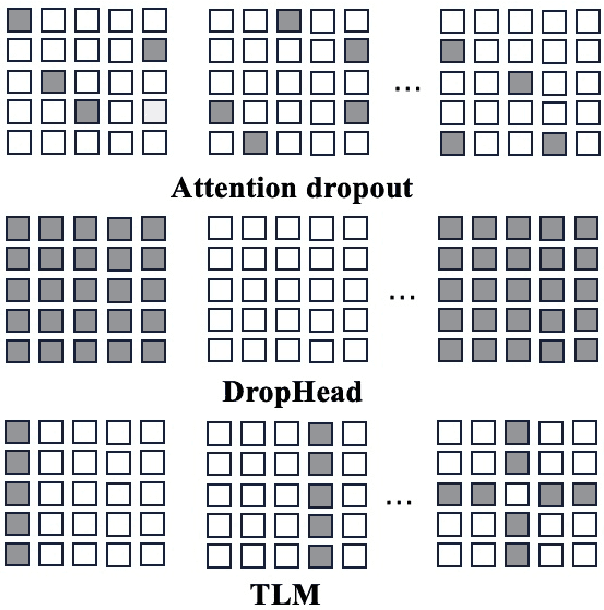

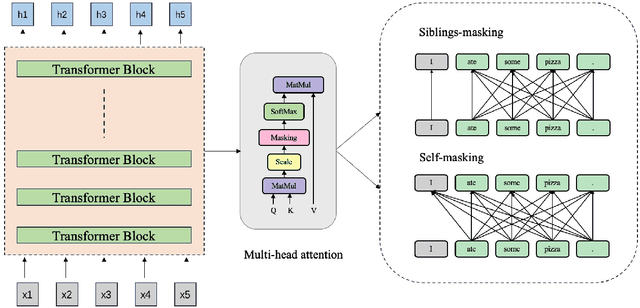

Structured dropout approaches, such as attention dropout and DropHead, have been investigated to regularize the multi-head attention mechanism in Transformers. In this paper, we propose a new regularization scheme based on token-level rather than structure-level to reduce overfitting. Specifically, we devise a novel Token-Level Masking (TLM) training strategy for Transformers to regularize the connections of self-attention, which consists of two masking techniques that are effective and easy to implement. The underlying idea is to manipulate the connections between tokens in the multi-head attention via masking, where the networks are forced to exploit partial neighbors' information to produce a meaningful representation. The generality and effectiveness of TLM are thoroughly evaluated via extensive experiments on 4 diversified NLP tasks across 18 datasets, including natural language understanding benchmark GLUE, ChineseGLUE, Chinese Grammatical Error Correction, and data-to-text generation. The results indicate that TLM can consistently outperform attention dropout and DropHead, e.g., it increases by 0.5 points relative to DropHead with BERT-large on GLUE. Moreover, TLM can establish a new record on the data-to-text benchmark Rotowire (18.93 BLEU). Our code will be publicly available at https://github.com/Young1993/tlm.
NNQS-Transformer: an Efficient and Scalable Neural Network Quantum States Approach for Ab initio Quantum Chemistry
Jul 01, 2023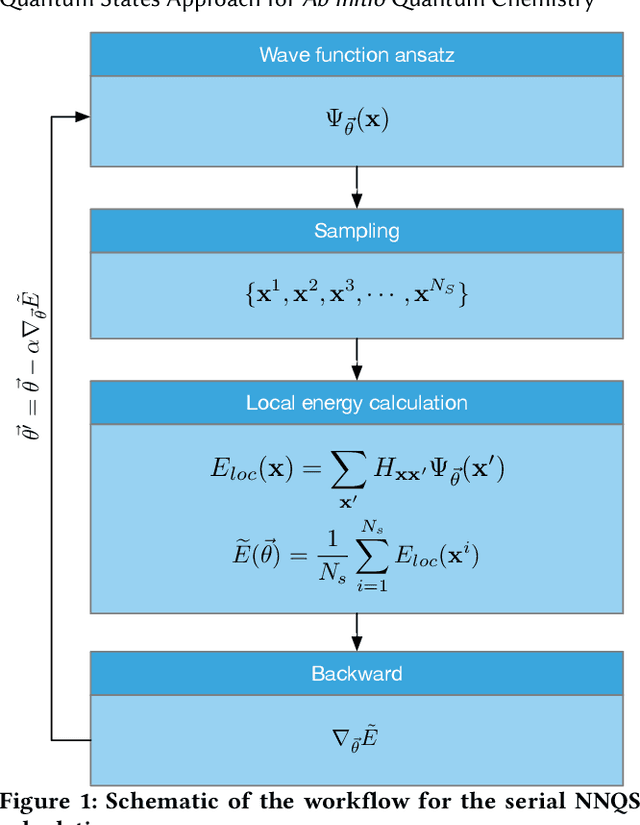
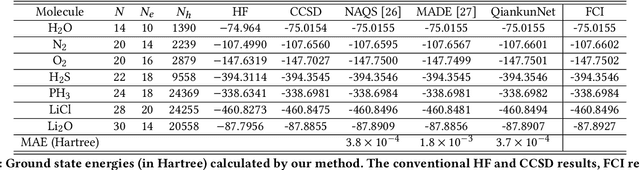
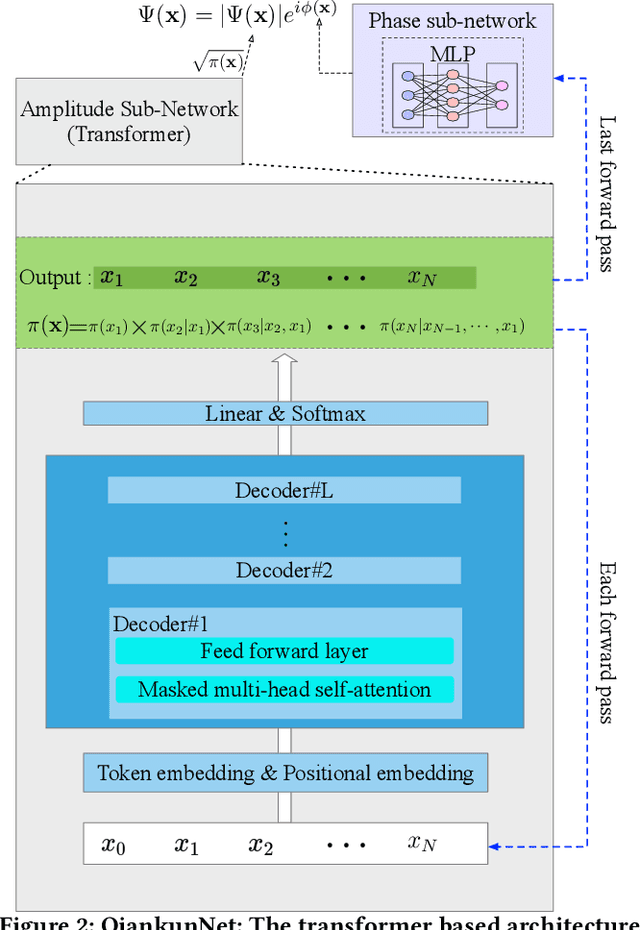
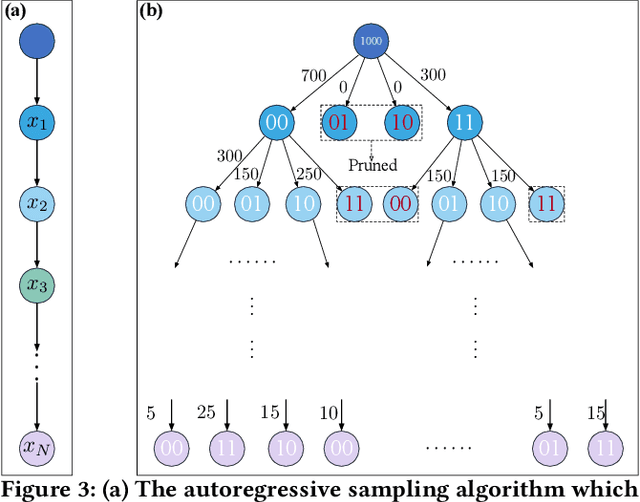
Neural network quantum state (NNQS) has emerged as a promising candidate for quantum many-body problems, but its practical applications are often hindered by the high cost of sampling and local energy calculation. We develop a high-performance NNQS method for \textit{ab initio} electronic structure calculations. The major innovations include: (1) A transformer based architecture as the quantum wave function ansatz; (2) A data-centric parallelization scheme for the variational Monte Carlo (VMC) algorithm which preserves data locality and well adapts for different computing architectures; (3) A parallel batch sampling strategy which reduces the sampling cost and achieves good load balance; (4) A parallel local energy evaluation scheme which is both memory and computationally efficient; (5) Study of real chemical systems demonstrates both the superior accuracy of our method compared to state-of-the-art and the strong and weak scalability for large molecular systems with up to $120$ spin orbitals.
FF2: A Feature Fusion Two-Stream Framework for Punctuation Restoration
Nov 09, 2022



To accomplish punctuation restoration, most existing methods focus on introducing extra information (e.g., part-of-speech) or addressing the class imbalance problem. Recently, large-scale transformer-based pre-trained language models (PLMS) have been utilized widely and obtained remarkable success. However, the PLMS are trained on the large dataset with marks, which may not fit well with the small dataset without marks, causing the convergence to be not ideal. In this study, we propose a Feature Fusion two-stream framework (FF2) to bridge the gap. Specifically, one stream leverages a pre-trained language model to capture the semantic feature, while another auxiliary module captures the feature at hand. We also modify the computation of multi-head attention to encourage communication among heads. Then, two features with different perspectives are aggregated to fuse information and enhance context awareness. Without additional data, the experimental results on the popular benchmark IWSLT demonstrate that FF2 achieves new SOTA performance, which verifies that our approach is effective.
A Context-Aware Feature Fusion Framework for Punctuation Restoration
Mar 23, 2022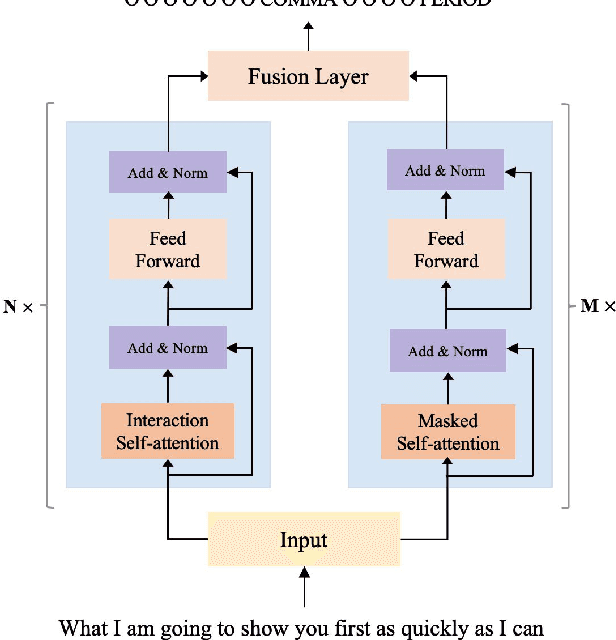
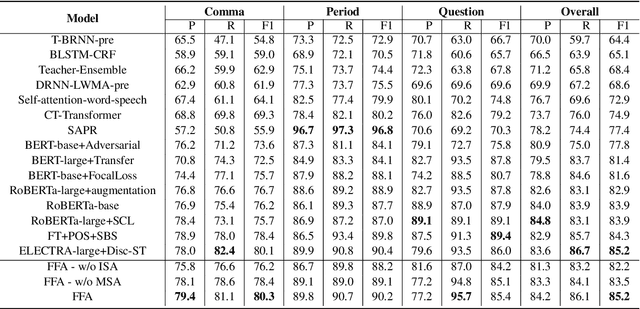
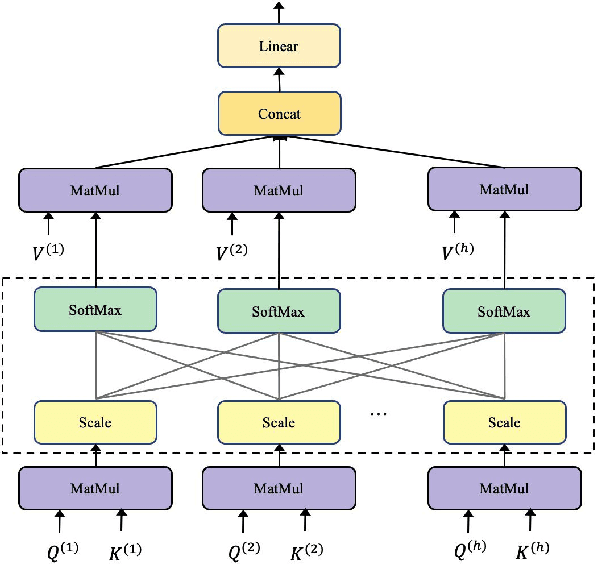
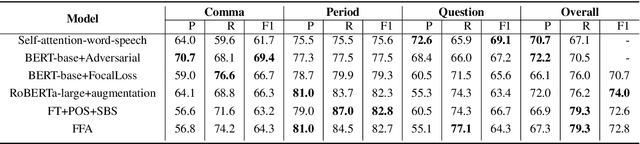
To accomplish the punctuation restoration task, most existing approaches focused on leveraging extra information (e.g., part-of-speech tags) or addressing the class imbalance problem. Recent works have widely applied the transformer-based language models and significantly improved their effectiveness. To the best of our knowledge, an inherent issue has remained neglected: the attention of individual heads in the transformer will be diluted or powerless while feeding the long non-punctuation utterances. Since those previous contexts, not the followings, are comparatively more valuable to the current position, it's hard to achieve a good balance by independent attention. In this paper, we propose a novel Feature Fusion framework based on two-type Attentions (FFA) to alleviate the shortage. It introduces a two-stream architecture. One module involves interaction between attention heads to encourage the communication, and another masked attention module captures the dependent feature representation. Then, it aggregates two feature embeddings to fuse information and enhances context-awareness. The experiments on the popular benchmark dataset IWSLT demonstrate that our approach is effective. Without additional data, it obtains comparable performance to the current state-of-the-art models.