 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating a Math Word Problem to an Expression Tree
Paper and Code
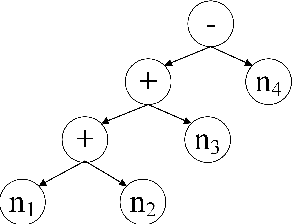
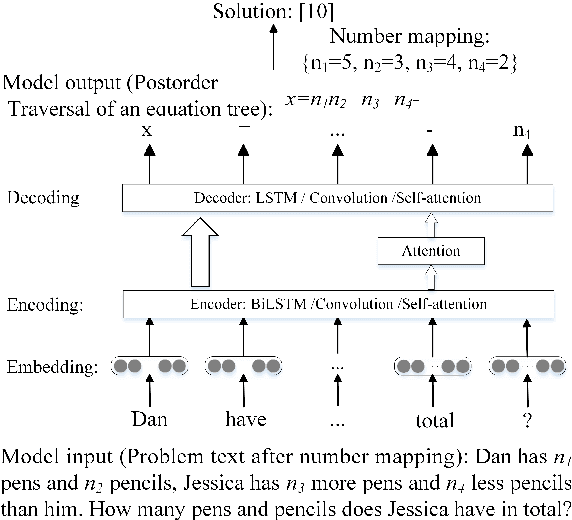
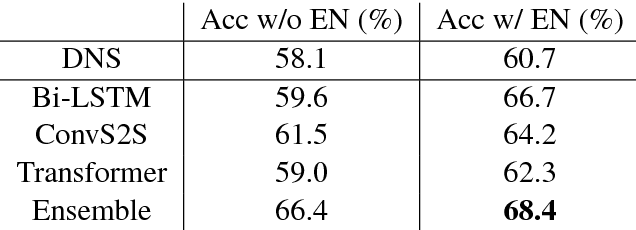
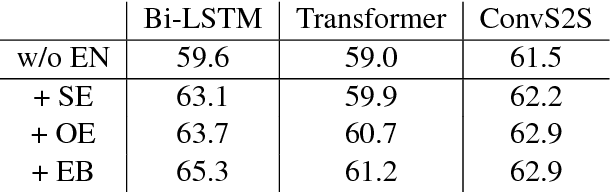
Sequence-to-sequence (SEQ2SEQ) models have been successfully applied to automatic math word problem solving. Despite its simplicity, a drawback still remains: a math word problem can be correctly solved by more than one equations. This non-deterministic transduction harms the performance of maximum likelihood estimation. In this paper, by considering the uniqueness of expression tree, we propose an equation normalization method to normalize the duplicated equations. Moreover, we analyze the performance of three popular SEQ2SEQ models on the math word problem solving. We find that each model has its own specialty in solving problems, consequently an ensemble model is then proposed to combine their advantages. Experiments on dataset Math23K show that the ensemble model with equation normalization significantly outperforms the previous state-of-the-art methods.