 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle Diffusion Matching: Random Walk Correspondence Search for the Alignment of Standard and Ultra-Widefield Fundus Images
Apr 11, 2026We propose a robust alignment technique for Standard Fundus Images (SFIs) and Ultra-Widefield Fundus Images (UWFIs), which are challenging to align due to differences in scale, appearance, and the scarcity of distinctive features. Our method, termed Particle Diffusion Matching (PDM), performs alignment through an iterative Random Walk Correspondence Search (RWCS) guided by a diffusion model. At each iteration, the model estimates displacement vectors for particle points by considering local appearance, the structural distribution of particles, and an estimated global transformation, enabling progressive refinement of correspondences even under difficult conditions. PDM achieves state-of-the-art performance across multiple retinal image alignment benchmarks, showing substantial improvement on a primary dataset of SFI-UWFI pairs and demonstrating its effectiveness in real-world clinical scenarios. By providing accurate and scalable correspondence estimation, PDM overcomes the limitations of existing methods and facilitates the integration of complementary retinal image modalities. This diffusion-guided search strategy offers a new direction for improving downstream supervised learning, disease diagnosis, and multi-modal image analysis in ophthalmology.
Active Diffusion Matching: Score-based Iterative Alignment of Cross-Modal Retinal Images
Apr 11, 2026Objective: The study aims to address the challenge of aligning Standard Fundus Images (SFIs) and Ultra-Widefield Fundus Images (UWFIs), which is difficult due to their substantial differences in viewing range and the amorphous appearance of the retina. Currently, no specialized method exists for this task, and existing image alignment techniques lack accuracy. Methods: We propose Active Diffusion Matching (ADM), a novel cross-modal alignment method. ADM integrates two interdependent score-based diffusion models to jointly estimate global transformations and local deformations via an iterative Langevin Markov chain. This approach facilitates a stochastic, progressive search for optimal alignment. Additionally, custom sampling strategies are introduced to enhance the adaptability of ADM to given input image pairs. Results: Comparative experimental evaluations demonstrate that ADM achieves state-of-the-art alignment accuracy. This was validated on two datasets: a private dataset of SFI-UWFI pairs and a public dataset of SFI-SFI pairs, with mAUC improvements of 5.2 and 0.4 points on the private and public datasets, respectively, compared to existing state-of-the-art methods. Conclusion: ADM effectively bridges the gap in aligning SFIs and UWFIs, providing an innovative solution to a previously unaddressed challenge. The method's ability to jointly optimize global and local alignment makes it highly effective for cross-modal image alignment tasks. Significance: ADM has the potential to transform the integrated analysis of SFIs and UWFIs, enabling better clinical utility and supporting learning-based image enhancements. This advancement could significantly improve diagnostic accuracy and patient outcomes in ophthalmology.
MatRes: Zero-Shot Test-Time Model Adaptation for Simultaneous Matching and Restoration
Apr 11, 2026Real-world image pairs often exhibit both severe degradations and large viewpoint changes, making image restoration and geometric matching mutually interfering tasks when treated independently. In this work, we propose MatRes, a zero-shot test-time adaptation framework that jointly improves restoration quality and correspondence estimation using only a single low-quality and high-quality image pair. By enforcing conditional similarity at corresponding locations, MatRes updates only lightweight modules while keeping all pretrained components frozen, requiring no offline training or additional supervision. Extensive experiments across diverse combinations show that MatRes yields significant gains in both restoration and geometric alignment compared to using either restoration or matching models alone. MatRes offers a practical and widely applicable solution for real-world scenarios where users commonly capture multiple images of a scene with varying viewpoints and quality, effectively addressing the often-overlooked mutual interference between matching and restoration.
Reasoning-Augmented Representations for Multimodal Retrieval
Feb 06, 2026Universal Multimodal Retrieval (UMR) seeks any-to-any search across text and vision, yet modern embedding models remain brittle when queries require latent reasoning (e.g., resolving underspecified references or matching compositional constraints). We argue this brittleness is often data-induced: when images carry "silent" evidence and queries leave key semantics implicit, a single embedding pass must both reason and compress, encouraging spurious feature matching. We propose a data-centric framework that decouples these roles by externalizing reasoning before retrieval. Using a strong Vision--Language Model, we make implicit semantics explicit by densely captioning visual evidence in corpus entries, resolving ambiguous multimodal references in queries, and rewriting verbose instructions into concise retrieval constraints. Inference-time enhancement alone is insufficient; the retriever must be trained on these semantically dense representations to avoid distribution shift and fully exploit the added signal. Across M-BEIR, our reasoning-augmented training method yields consistent gains over strong baselines, with ablations showing that corpus enhancement chiefly benefits knowledge-intensive queries while query enhancement is critical for compositional modification requests. We publicly release our code at https://github.com/AugmentedRetrieval/ReasoningAugmentedRetrieval.
Contamination Detection for VLMs using Multi-Modal Semantic Perturbation
Nov 05, 2025Recent advances in Vision-Language Models (VLMs) have achieved state-of-the-art performance on numerous benchmark tasks. However, the use of internet-scale, often proprietary, pretraining corpora raises a critical concern for both practitioners and users: inflated performance due to test-set leakage. While prior works have proposed mitigation strategies such as decontamination of pretraining data and benchmark redesign for LLMs, the complementary direction of developing detection methods for contaminated VLMs remains underexplored. To address this gap, we deliberately contaminate open-source VLMs on popular benchmarks and show that existing detection approaches either fail outright or exhibit inconsistent behavior. We then propose a novel simple yet effective detection method based on multi-modal semantic perturbation, demonstrating that contaminated models fail to generalize under controlled perturbations. Finally, we validate our approach across multiple realistic contamination strategies, confirming its robustness and effectiveness. The code and perturbed dataset will be released publicly.
UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
May 28, 2025We present UniTalk, a novel dataset specifically designed for the task of active speaker detection, emphasizing challenging scenarios to enhance model generalization. Unlike previously established benchmarks such as AVA, which predominantly features old movies and thus exhibits significant domain gaps, UniTalk focuses explicitly on diverse and difficult real-world conditions. These include underrepresented languages, noisy backgrounds, and crowded scenes - such as multiple visible speakers speaking concurrently or in overlapping turns. It contains over 44.5 hours of video with frame-level active speaker annotations across 48,693 speaking identities, and spans a broad range of video types that reflect real-world conditions. Through rigorous evaluation, we show that state-of-the-art models, while achieving nearly perfect scores on AVA, fail to reach saturation on UniTalk, suggesting that the ASD task remains far from solved under realistic conditions. Nevertheless, models trained on UniTalk demonstrate stronger generalization to modern "in-the-wild" datasets like Talkies and ASW, as well as to AVA. UniTalk thus establishes a new benchmark for active speaker detection, providing researchers with a valuable resource for developing and evaluating versatile and resilient models. Dataset: https://huggingface.co/datasets/plnguyen2908/UniTalk-ASD Code: https://github.com/plnguyen2908/UniTalk-ASD-code
Auto-regressive transformation for image alignment
May 08, 2025



Existing methods for image alignment struggle in cases involving feature-sparse regions, extreme scale and field-of-view differences, and large deformations, often resulting in suboptimal accuracy. Robustness to these challenges improves through iterative refinement of the transformation field while focusing on critical regions in multi-scale image representations. We thus propose Auto-Regressive Transformation (ART), a novel method that iteratively estimates the coarse-to-fine transformations within an auto-regressive framework. Leveraging hierarchical multi-scale features, our network refines the transformations using randomly sampled points at each scale. By incorporating guidance from the cross-attention layer, the model focuses on critical regions, ensuring accurate alignment even in challenging, feature-limited conditions. Extensive experiments across diverse datasets demonstrate that ART significantly outperforms state-of-the-art methods, establishing it as a powerful new method for precise image alignment with broad applicability.
CoAPT: Context Attribute words for Prompt Tuning
Jul 18, 2024



We propose a novel prompt tuning method called CoAPT(Context Attribute words in Prompt Tuning) for few/zero-shot image classification. The core motivation is that attributes are descriptive words with rich information about a given concept. Thus, we aim to enrich text queries of existing prompt tuning methods, improving alignment between text and image embeddings in CLIP embedding space. To do so, CoAPT integrates attribute words as additional prompts within learnable prompt tuning and can be easily incorporated into various existing prompt tuning methods. To facilitate the incorporation of attributes into text embeddings and the alignment with image embeddings, soft prompts are trained together with an additional meta-network that generates input-image-wise feature biases from the concatenated feature encodings of the image-text combined queries. Our experiments demonstrate that CoAPT leads to considerable improvements for existing baseline methods on several few/zero-shot image classification tasks, including base-to-novel generalization, cross-dataset transfer, and domain generalization. Our findings highlight the importance of combining hard and soft prompts and pave the way for future research on the interplay between text and image latent spaces in pre-trained models.
Generation of Structurally Realistic Retinal Fundus Images with Diffusion Models
May 11, 2023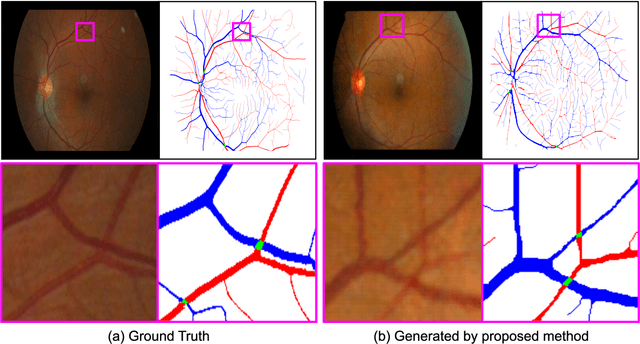
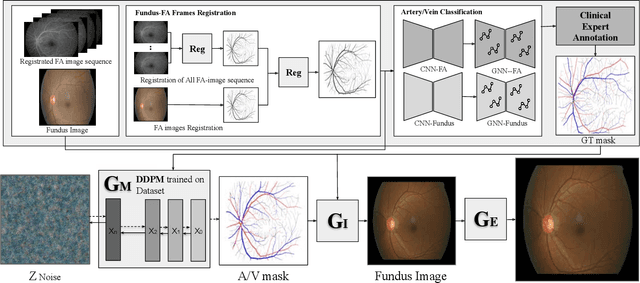
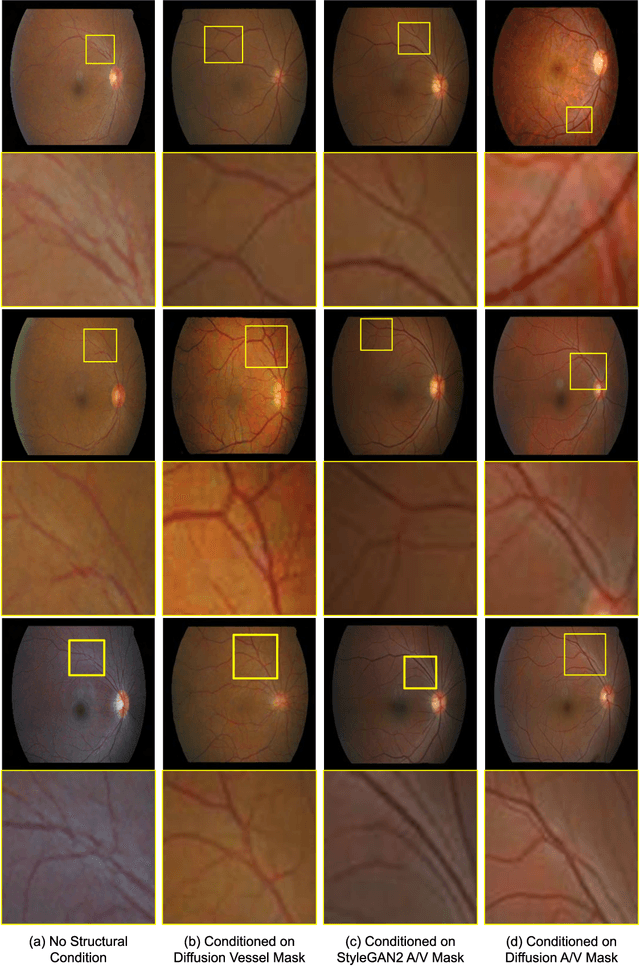
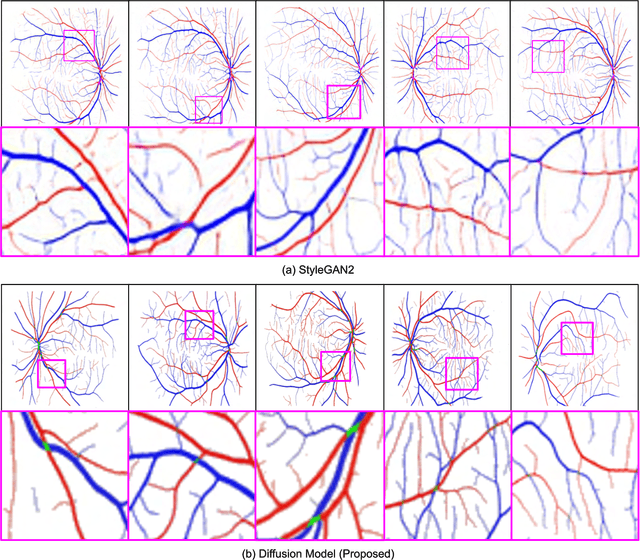
We introduce a new technique for generating retinal fundus images that have anatomically accurate vascular structures, using diffusion models. We generate artery/vein masks to create the vascular structure, which we then condition to produce retinal fundus images. The proposed method can generate high-quality images with more realistic vascular structures and can create a diverse range of images based on the strengths of the diffusion model. We present quantitative evaluations that demonstrate the performance improvement using our method for data augmentation on vessel segmentation and artery/vein classification. We also present Turing test results by clinical experts, showing that our generated images are difficult to distinguish with real images. We believe that our method can be applied to construct stand-alone datasets that are irrelevant of patient privacy.
Extraction of Coronary Vessels in Fluoroscopic X-Ray Sequences Using Vessel Correspondence Optimization
Jul 28, 2022We present a method to extract coronary vessels from fluoroscopic x-ray sequences. Given the vessel structure for the source frame, vessel correspondence candidates in the subsequent frame are generated by a novel hierarchical search scheme to overcome the aperture problem. Optimal correspondences are determined within a Markov random field optimization framework. Post-processing is performed to extract vessel branches newly visible due to the inflow of contrast agent. Quantitative and qualitative evaluation conducted on a dataset of 18 sequences demonstrates the effectiveness of the proposed method.