 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning by Asymmetric Loss Approximation with Single-Side Overestimation
Paper and Code
Aug 08, 2019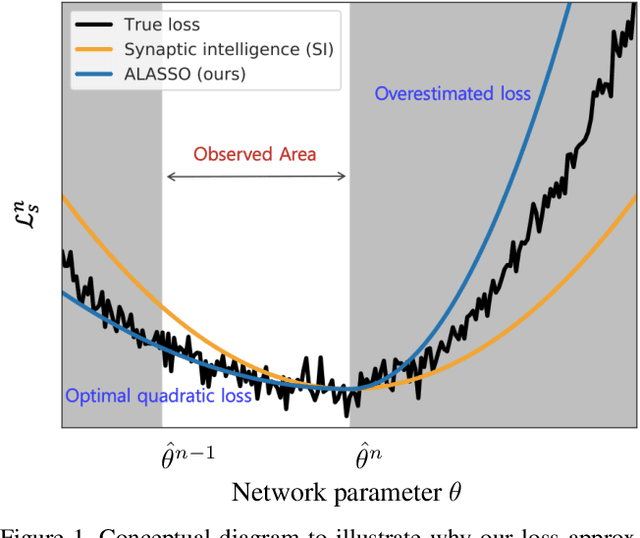



Catastrophic forgetting is a critical challenge in training deep neural networks. Although continual learning has been investigated as a countermeasure to the problem, it often suffers from requirements of additional network components and weak scalability to a large number of tasks. We propose a novel approach to continual learning by approximating a true loss function based on an asymmetric quadratic function with one of its sides overestimated. Our algorithm is motivated by the empirical observation that updates of network parameters affect target loss functions asymmetrically. In the proposed continual learning framework, we estimate an asymmetric loss function for the tasks considered in the past through a proper overestimation of its unobserved side in training new tasks, while deriving the accurate model parameter for the observed side. In contrast to existing approaches, our method is free from side effects and achieves the state-of-the-art results that are even close to the upper-bound performance on several challenging benchmark datasets.