 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubSpectral Normalization for Neural Audio Data Processing
Paper and Code
Mar 25, 2021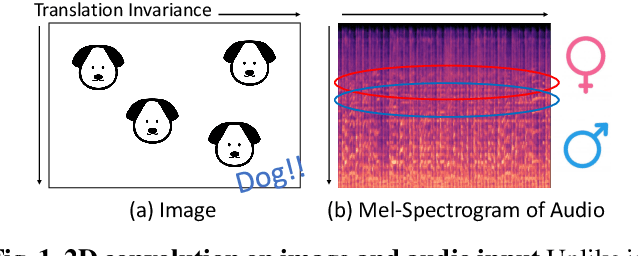

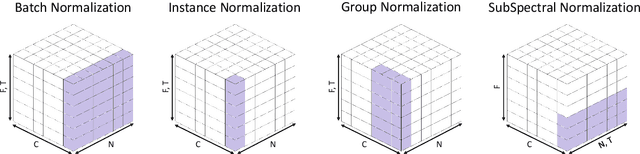
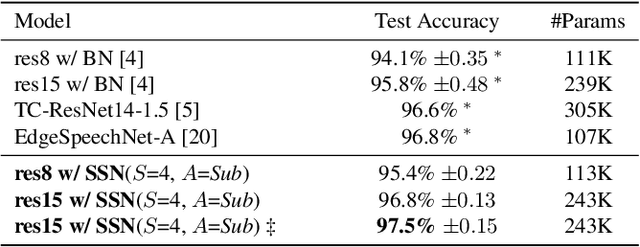
Convolutional Neural Networks are widely used in various machine learning domains. In image processing, the features can be obtained by applying 2D convolution to all spatial dimensions of the input. However, in the audio case, frequency domain input like Mel-Spectrogram has different and unique characteristics in the frequency dimension. Thus, there is a need for a method that allows the 2D convolution layer to handle the frequency dimension differently. In this work, we introduce SubSpectral Normalization (SSN), which splits the input frequency dimension into several groups (sub-bands) and performs a different normalization for each group. SSN also includes an affine transformation that can be applied to each group. Our method removes the inter-frequency deflection while the network learns a frequency-aware characteristic. In the experiments with audio data, we observed that SSN can efficiently improve the network's performance.