 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
Paper and Code
May 17, 2022
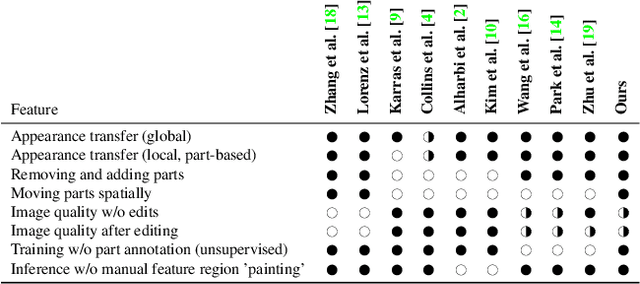
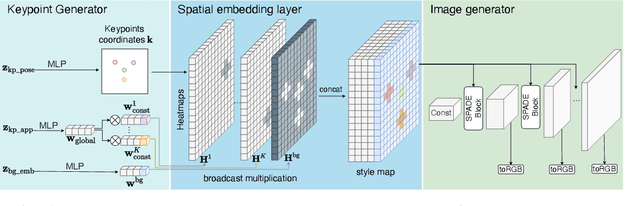
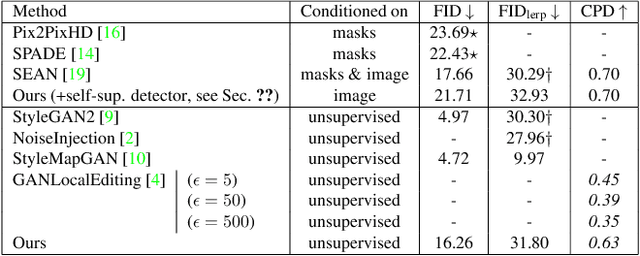
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.