 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Paper and Code

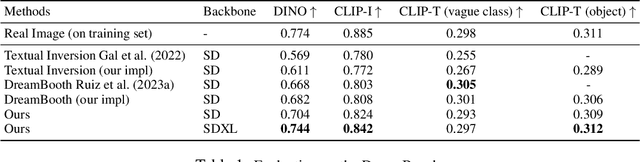

Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.