 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANSeg: Learning to Segment by Unsupervised Hierarchical Image Generation
Paper and Code

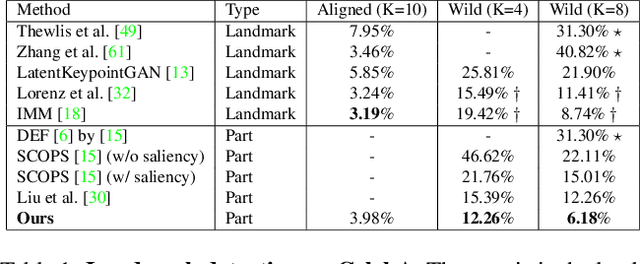
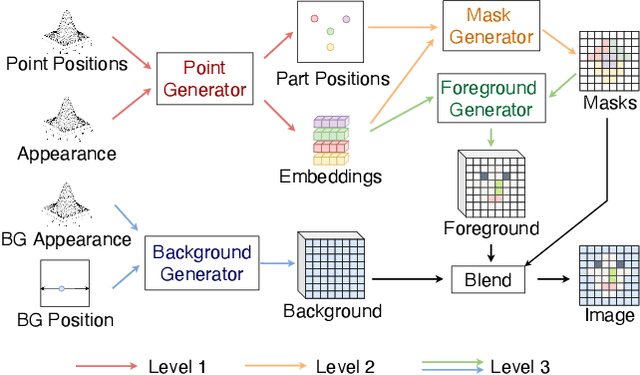
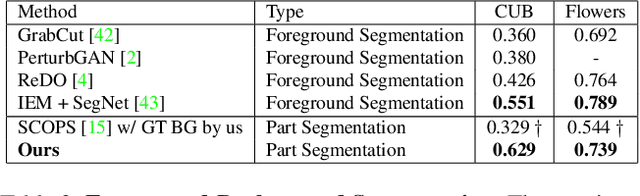
Segmenting an image into its parts is a frequent preprocess for high-level vision tasks such as image editing. However, annotating masks for supervised training is expensive. Weakly-supervised and unsupervised methods exist, but they depend on the comparison of pairs of images, such as from multi-views, frames of videos, and image transformations of single images, which limits their applicability. To address this, we propose a GAN-based approach that generates images conditioned on latent masks, thereby alleviating full or weak annotations required in previous approaches. We show that such mask-conditioned image generation can be learned faithfully when conditioning the masks in a hierarchical manner on latent keypoints that define the position of parts explicitly. Without requiring supervision of masks or points, this strategy increases robustness to viewpoint and object positions changes. It also lets us generate image-mask pairs for training a segmentation network, which outperforms the state-of-the-art unsupervised segmentation methods on established benchmarks.