 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Imitation Learning with Suboptimal Demonstrations via Relaxed Distribution Matching
Paper and Code



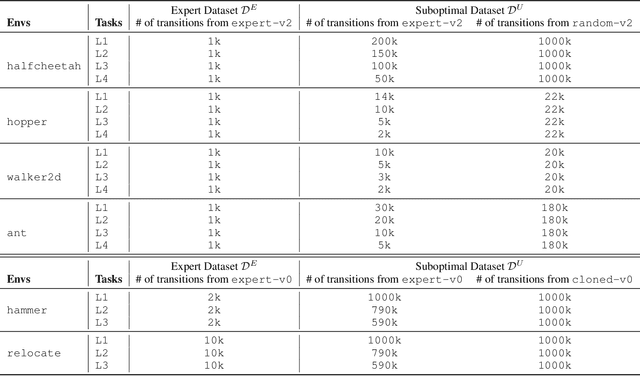
Offline imitation learning (IL) promises the ability to learn performant policies from pre-collected demonstrations without interactions with the environment. However, imitating behaviors fully offline typically requires numerous expert data. To tackle this issue, we study the setting where we have limited expert data and supplementary suboptimal data. In this case, a well-known issue is the distribution shift between the learned policy and the behavior policy that collects the offline data. Prior works mitigate this issue by regularizing the KL divergence between the stationary state-action distributions of the learned policy and the behavior policy. We argue that such constraints based on exact distribution matching can be overly conservative and hamper policy learning, especially when the imperfect offline data is highly suboptimal. To resolve this issue, we present RelaxDICE, which employs an asymmetrically-relaxed f-divergence for explicit support regularization. Specifically, instead of driving the learned policy to exactly match the behavior policy, we impose little penalty whenever the density ratio between their stationary state-action distributions is upper bounded by a constant. Note that such formulation leads to a nested min-max optimization problem, which causes instability in practice. RelaxDICE addresses this challenge by supporting a closed-form solution for the inner maximization problem. Extensive empirical study shows that our method significantly outperforms the best prior offline IL method in six standard continuous control environments with over 30% performance gain on average, across 22 settings where the imperfect dataset is highly suboptimal.