 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Free Learning of a Natural Language Interface for Pretrained Face Generators
Paper and Code
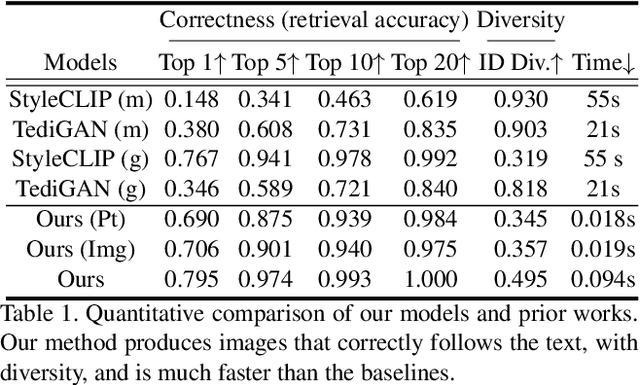
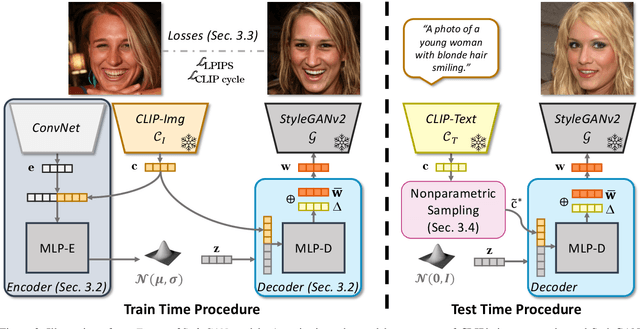
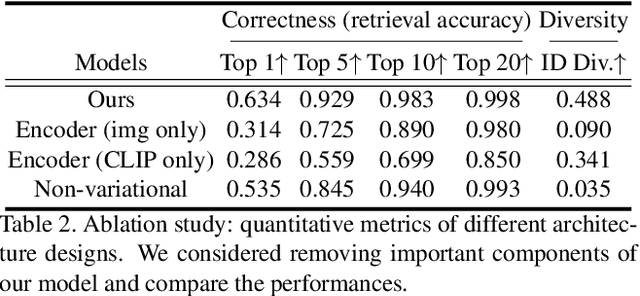

We propose Fast text2StyleGAN, a natural language interface that adapts pre-trained GANs for text-guided human face synthesis. Leveraging the recent advances in Contrastive Language-Image Pre-training (CLIP), no text data is required during training. Fast text2StyleGAN is formulated as a conditional variational autoencoder (CVAE) that provides extra control and diversity to the generated images at test time. Our model does not require re-training or fine-tuning of the GANs or CLIP when encountering new text prompts. In contrast to prior work, we do not rely on optimization at test time, making our method orders of magnitude faster than prior work. Empirically, on FFHQ dataset, our method offers faster and more accurate generation of images from natural language descriptions with varying levels of detail compared to prior work.