 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLOT-TAL -- Prompt Learning with Optimal Transport for Few-Shot Temporal Action Localization
Mar 27, 2024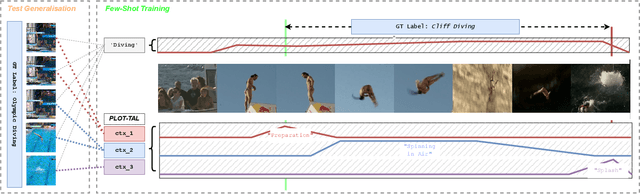
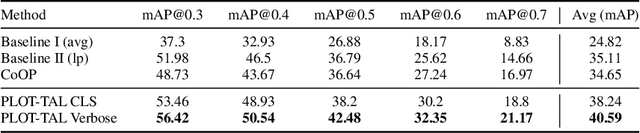
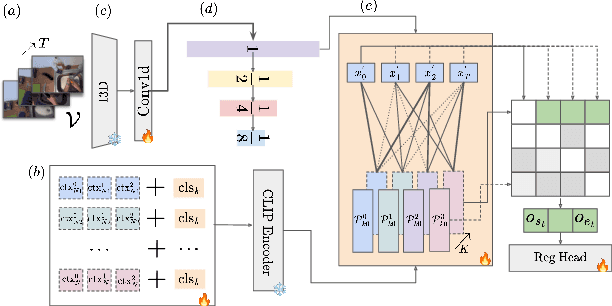

This paper introduces a novel approach to temporal action localization (TAL) in few-shot learning. Our work addresses the inherent limitations of conventional single-prompt learning methods that often lead to overfitting due to the inability to generalize across varying contexts in real-world videos. Recognizing the diversity of camera views, backgrounds, and objects in videos, we propose a multi-prompt learning framework enhanced with optimal transport. This design allows the model to learn a set of diverse prompts for each action, capturing general characteristics more effectively and distributing the representation to mitigate the risk of overfitting. Furthermore, by employing optimal transport theory, we efficiently align these prompts with action features, optimizing for a comprehensive representation that adapts to the multifaceted nature of video data. Our experiments demonstrate significant improvements in action localization accuracy and robustness in few-shot settings on the standard challenging datasets of THUMOS-14 and EpicKitchens100, highlighting the efficacy of our multi-prompt optimal transport approach in overcoming the challenges of conventional few-shot TAL methods.
Multi-Resolution Audio-Visual Feature Fusion for Temporal Action Localization
Oct 05, 2023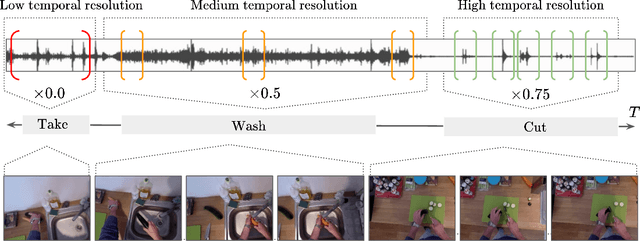
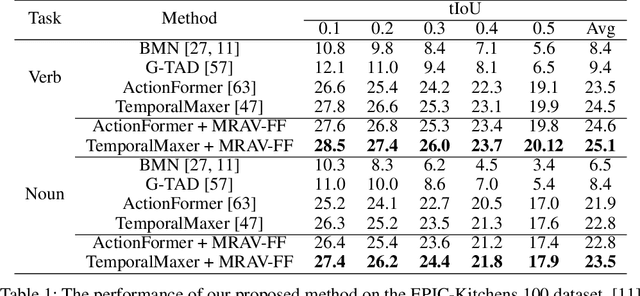
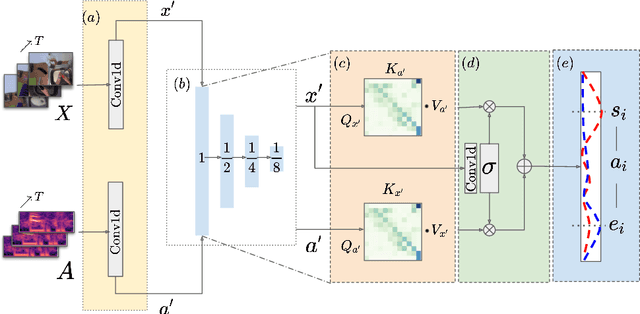
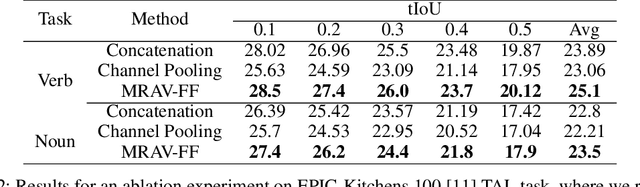
Temporal Action Localization (TAL) aims to identify actions' start, end, and class labels in untrimmed videos. While recent advancements using transformer networks and Feature Pyramid Networks (FPN) have enhanced visual feature recognition in TAL tasks, less progress has been made in the integration of audio features into such frameworks. This paper introduces the Multi-Resolution Audio-Visual Feature Fusion (MRAV-FF), an innovative method to merge audio-visual data across different temporal resolutions. Central to our approach is a hierarchical gated cross-attention mechanism, which discerningly weighs the importance of audio information at diverse temporal scales. Such a technique not only refines the precision of regression boundaries but also bolsters classification confidence. Importantly, MRAV-FF is versatile, making it compatible with existing FPN TAL architectures and offering a significant enhancement in performance when audio data is available.
Two-Stream Transformer Architecture for Long Video Understanding
Aug 02, 2022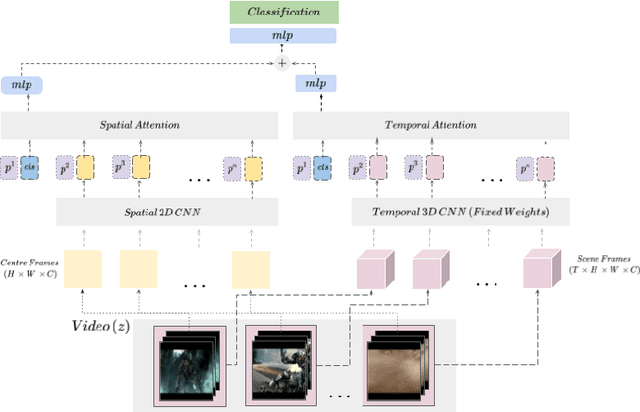
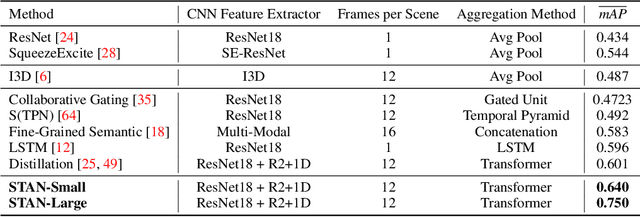
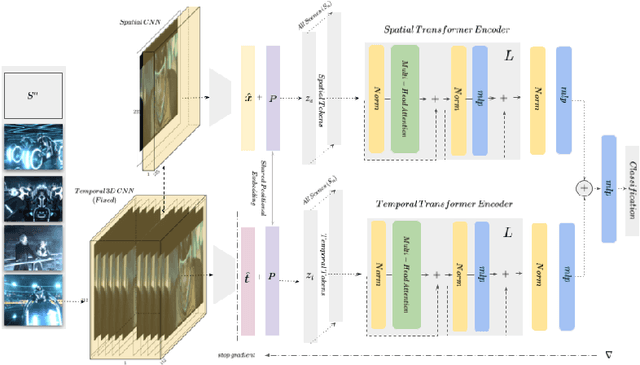
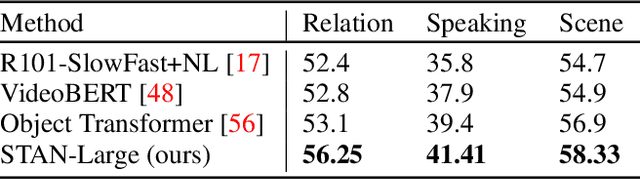
Pure vision transformer architectures are highly effective for short video classification and action recognition tasks. However, due to the quadratic complexity of self attention and lack of inductive bias, transformers are resource intensive and suffer from data inefficiencies. Long form video understanding tasks amplify data and memory efficiency problems in transformers making current approaches unfeasible to implement on data or memory restricted domains. This paper introduces an efficient Spatio-Temporal Attention Network (STAN) which uses a two-stream transformer architecture to model dependencies between static image features and temporal contextual features. Our proposed approach can classify videos up to two minutes in length on a single GPU, is data efficient, and achieves SOTA performance on several long video understanding tasks.
Rethinking movie genre classification with fine-grained semantic clustering
Dec 07, 2020
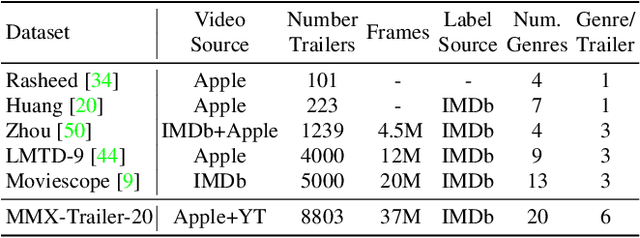
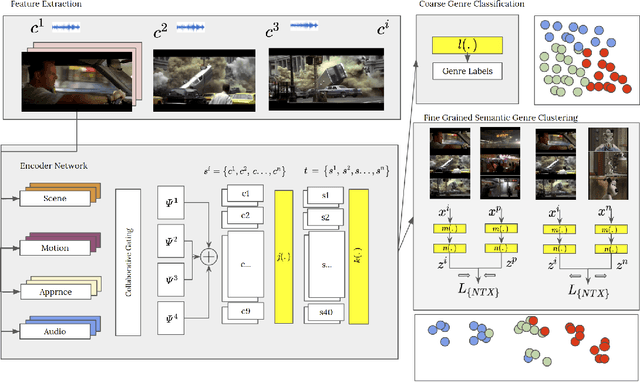
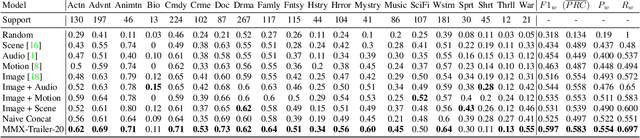
Movie genre classification is an active research area in machine learning. However, due to the limited labels available, there can be large semantic variations between movies within a single genre definition. We expand these 'coarse' genre labels by identifying 'fine-grained' semantic information within the multi-modal content of movies. By leveraging pre-trained 'expert' networks, we learn the influence of different combinations of modes for multi-label genre classification. Using a contrastive loss, we continue to fine-tune this 'coarse' genre classification network to identify high-level intertextual similarities between the movies across all genre labels. This leads to a more 'fine-grained' and detailed clustering, based on semantic similarities while still retaining some genre information. Our approach is demonstrated on a newly introduced multi-modal 37,866,450 frame, 8,800 movie trailer dataset, MMX-Trailer-20, which includes pre-computed audio, location, motion, and image embeddings.