 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stream Transformer Architecture for Long Video Understanding
Paper and Code
Aug 02, 2022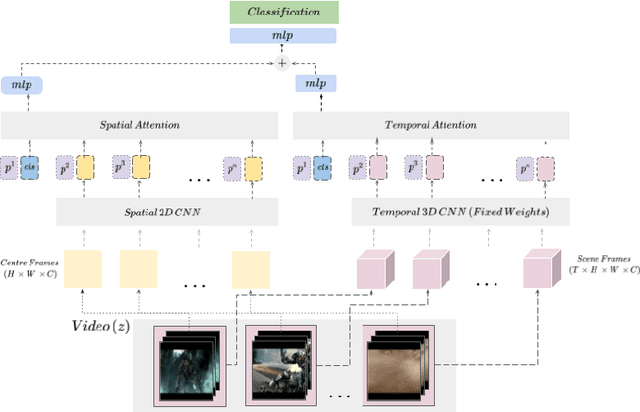
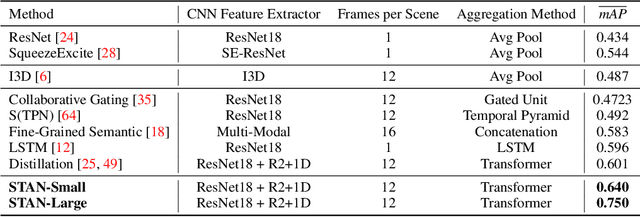
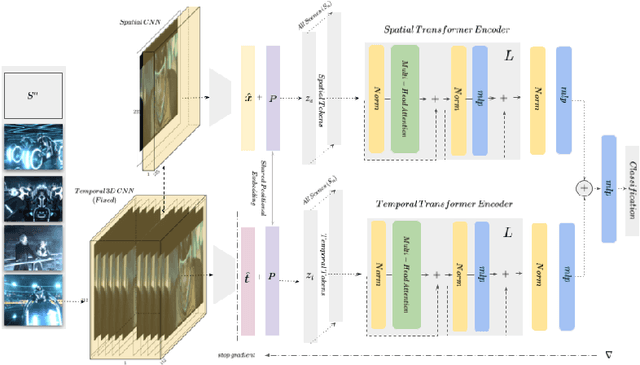
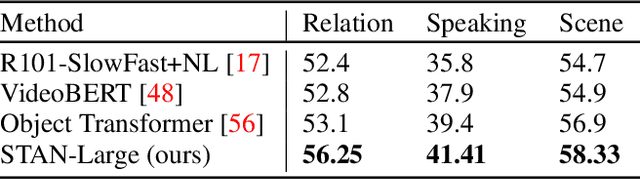
Pure vision transformer architectures are highly effective for short video classification and action recognition tasks. However, due to the quadratic complexity of self attention and lack of inductive bias, transformers are resource intensive and suffer from data inefficiencies. Long form video understanding tasks amplify data and memory efficiency problems in transformers making current approaches unfeasible to implement on data or memory restricted domains. This paper introduces an efficient Spatio-Temporal Attention Network (STAN) which uses a two-stream transformer architecture to model dependencies between static image features and temporal contextual features. Our proposed approach can classify videos up to two minutes in length on a single GPU, is data efficient, and achieves SOTA performance on several long video understanding tasks.