 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Resolution Audio-Visual Feature Fusion for Temporal Action Localization
Paper and Code
Oct 05, 2023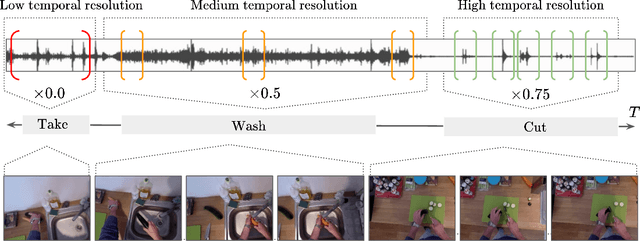
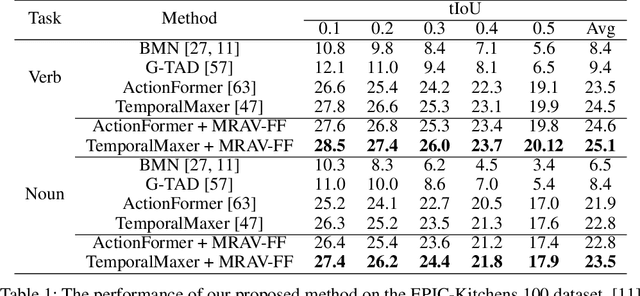
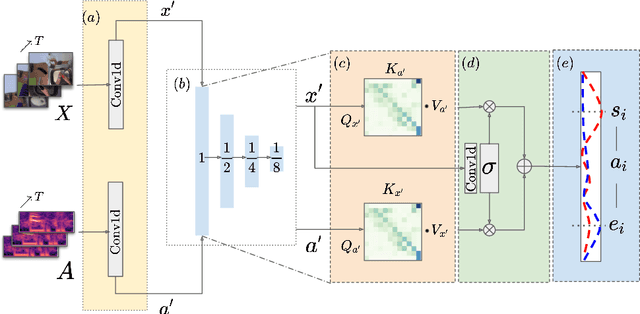
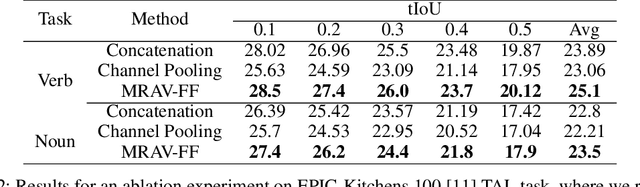
Temporal Action Localization (TAL) aims to identify actions' start, end, and class labels in untrimmed videos. While recent advancements using transformer networks and Feature Pyramid Networks (FPN) have enhanced visual feature recognition in TAL tasks, less progress has been made in the integration of audio features into such frameworks. This paper introduces the Multi-Resolution Audio-Visual Feature Fusion (MRAV-FF), an innovative method to merge audio-visual data across different temporal resolutions. Central to our approach is a hierarchical gated cross-attention mechanism, which discerningly weighs the importance of audio information at diverse temporal scales. Such a technique not only refines the precision of regression boundaries but also bolsters classification confidence. Importantly, MRAV-FF is versatile, making it compatible with existing FPN TAL architectures and offering a significant enhancement in performance when audio data is available.