 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFILS: Self-Supervised Video Feature Prediction In Semantic Language Space
Jun 05, 2024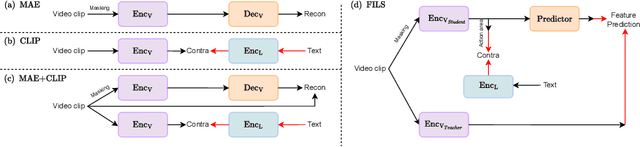
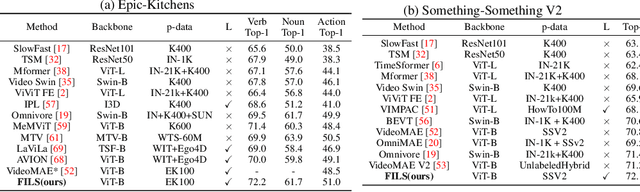
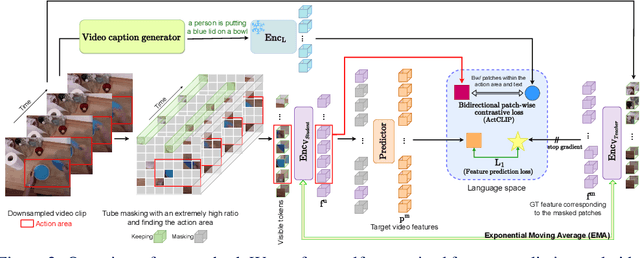
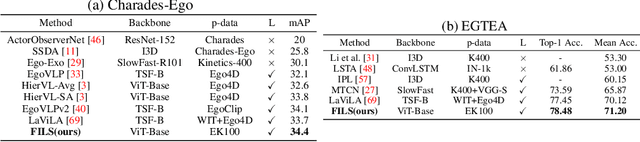
This paper demonstrates a self-supervised approach for learning semantic video representations. Recent vision studies show that a masking strategy for vision and natural language supervision has contributed to developing transferable visual pretraining. Our goal is to achieve a more semantic video representation by leveraging the text related to the video content during the pretraining in a fully self-supervised manner. To this end, we present FILS, a novel self-supervised video Feature prediction In semantic Language Space (FILS). The vision model can capture valuable structured information by correctly predicting masked feature semantics in language space. It is learned using a patch-wise video-text contrastive strategy, in which the text representations act as prototypes for transforming vision features into a language space, which are then used as targets for semantically meaningful feature prediction using our masked encoder-decoder structure. FILS demonstrates remarkable transferability on downstream action recognition tasks, achieving state-of-the-art on challenging egocentric datasets, like Epic-Kitchens, Something-SomethingV2, Charades-Ego, and EGTEA, using ViT-Base. Our efficient method requires less computation and smaller batches compared to previous works.
MOFO: MOtion FOcused Self-Supervision for Video Understanding
Aug 23, 2023Self-supervised learning (SSL) techniques have recently produced outstanding results in learning visual representations from unlabeled videos. Despite the importance of motion in supervised learning techniques for action recognition, SSL methods often do not explicitly consider motion information in videos. To address this issue, we propose MOFO (MOtion FOcused), a novel SSL method for focusing representation learning on the motion area of a video, for action recognition. MOFO automatically detects motion areas in videos and uses these to guide the self-supervision task. We use a masked autoencoder which randomly masks out a high proportion of the input sequence; we force a specified percentage of the inside of the motion area to be masked and the remainder from outside. We further incorporate motion information into the finetuning step to emphasise motion in the downstream task. We demonstrate that our motion-focused innovations can significantly boost the performance of the currently leading SSL method (VideoMAE) for action recognition. Our method improves the recent self-supervised Vision Transformer (ViT), VideoMAE, by achieving +2.6%, +2.1%, +1.3% accuracy on Epic-Kitchens verb, noun and action classification, respectively, and +4.7% accuracy on Something-Something V2 action classification. Our proposed approach significantly improves the performance of the current SSL method for action recognition, indicating the importance of explicitly encoding motion in SSL.
Heterogeneous Graph Learning for Acoustic Event Classification
Mar 12, 2023


Heterogeneous graphs provide a compact, efficient, and scalable way to model data involving multiple disparate modalities. This makes modeling audiovisual data using heterogeneous graphs an attractive option. However, graph structure does not appear naturally in audiovisual data. Graphs for audiovisual data are constructed manually which is both difficult and sub-optimal. In this work, we address this problem by (i) proposing a parametric graph construction strategy for the intra-modal edges, and (ii) learning the crossmodal edges. To this end, we develop a new model, heterogeneous graph crossmodal network (HGCN) that learns the crossmodal edges. Our proposed model can adapt to various spatial and temporal scales owing to its parametric construction, while the learnable crossmodal edges effectively connect the relevant nodes across modalities. Experiments on a large benchmark dataset (AudioSet) show that our model is state-of-the-art (0.53 mean average precision), outperforming transformer-based models and other graph-based models.