 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE: Saliency-Aware Counterfactual Explanations for DNN-based Automated Driving Systems
Jul 28, 2023



A CF explainer identifies the minimum modifications in the input that would alter the model's output to its complement. In other words, a CF explainer computes the minimum modifications required to cross the model's decision boundary. Current deep generative CF models often work with user-selected features rather than focusing on the discriminative features of the black-box model. Consequently, such CF examples may not necessarily lie near the decision boundary, thereby contradicting the definition of CFs. To address this issue, we propose in this paper a novel approach that leverages saliency maps to generate more informative CF explanations. Source codes are available at: https://github.com/Amir-Samadi//Saliency_Aware_CF.
Heterogeneous Graph Learning for Acoustic Event Classification
Mar 12, 2023


Heterogeneous graphs provide a compact, efficient, and scalable way to model data involving multiple disparate modalities. This makes modeling audiovisual data using heterogeneous graphs an attractive option. However, graph structure does not appear naturally in audiovisual data. Graphs for audiovisual data are constructed manually which is both difficult and sub-optimal. In this work, we address this problem by (i) proposing a parametric graph construction strategy for the intra-modal edges, and (ii) learning the crossmodal edges. To this end, we develop a new model, heterogeneous graph crossmodal network (HGCN) that learns the crossmodal edges. Our proposed model can adapt to various spatial and temporal scales owing to its parametric construction, while the learnable crossmodal edges effectively connect the relevant nodes across modalities. Experiments on a large benchmark dataset (AudioSet) show that our model is state-of-the-art (0.53 mean average precision), outperforming transformer-based models and other graph-based models.
Visually-aware Acoustic Event Detection using Heterogeneous Graphs
Jul 16, 2022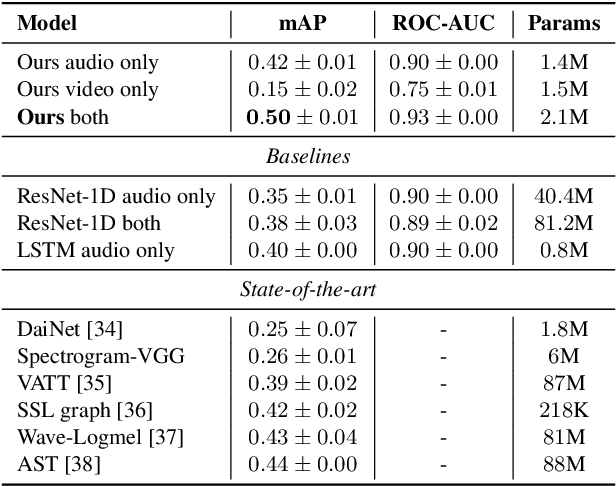

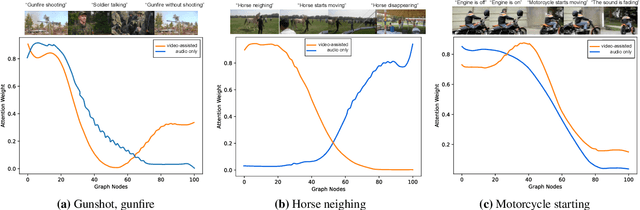
Perception of auditory events is inherently multimodal relying on both audio and visual cues. A large number of existing multimodal approaches process each modality using modality-specific models and then fuse the embeddings to encode the joint information. In contrast, we employ heterogeneous graphs to explicitly capture the spatial and temporal relationships between the modalities and represent detailed information about the underlying signal. Using heterogeneous graph approaches to address the task of visually-aware acoustic event classification, which serves as a compact, efficient and scalable way to represent data in the form of graphs. Through heterogeneous graphs, we show efficiently modelling of intra- and inter-modality relationships both at spatial and temporal scales. Our model can easily be adapted to different scales of events through relevant hyperparameters. Experiments on AudioSet, a large benchmark, shows that our model achieves state-of-the-art performance.
Self-supervised Graphs for Audio Representation Learning with Limited Labeled Data
Jan 31, 2022
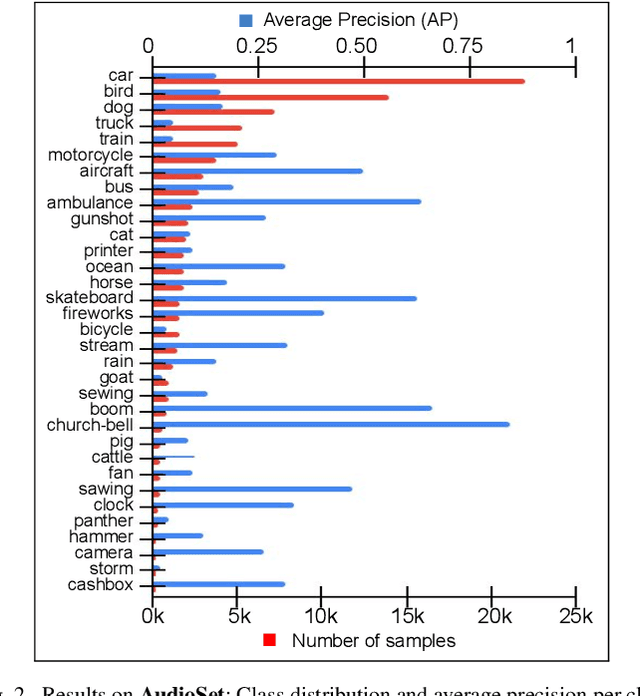
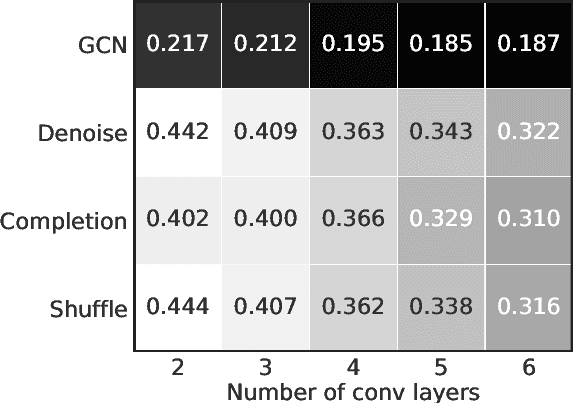
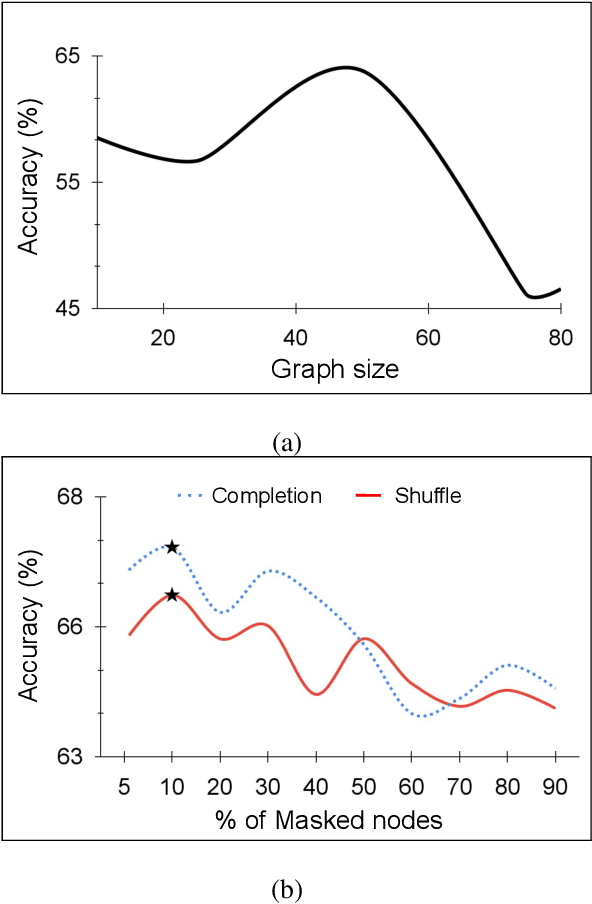
Large scale databases with high-quality manual annotations are scarce in audio domain. We thus explore a self-supervised graph approach to learning audio representations from highly limited labelled data. Considering each audio sample as a graph node, we propose a subgraph-based framework with novel self-supervision tasks that can learn effective audio representations. During training, subgraphs are constructed by sampling the entire pool of available training data to exploit the relationship between the labelled and unlabeled audio samples. During inference, we use random edges to alleviate the overhead of graph construction. We evaluate our model on three benchmark audio databases, and two tasks: acoustic event detection and speech emotion recognition. Our semi-supervised model performs better or on par with fully supervised models and outperforms several competitive existing models. Our model is compact (240k parameters), and can produce generalized audio representations that are robust to different types of signal noise.