 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Graphs for Audio Representation Learning with Limited Labeled Data
Paper and Code

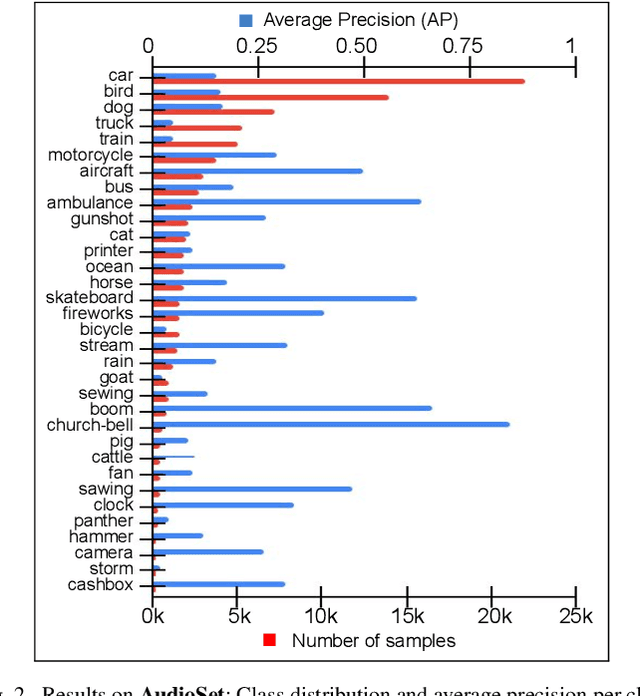
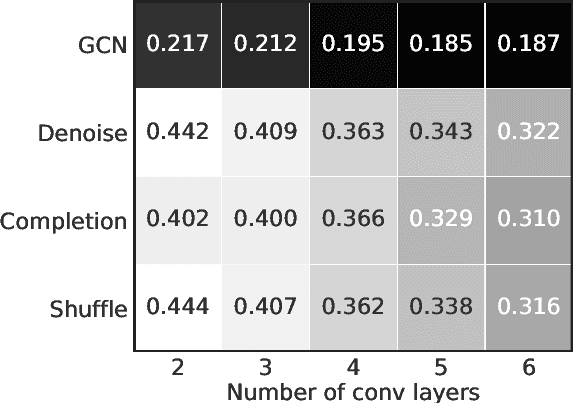
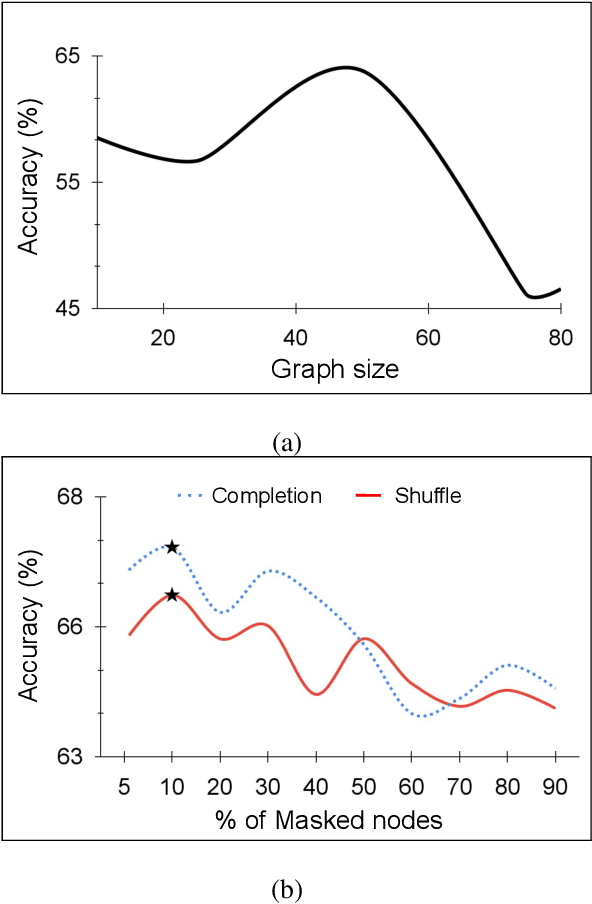
Large scale databases with high-quality manual annotations are scarce in audio domain. We thus explore a self-supervised graph approach to learning audio representations from highly limited labelled data. Considering each audio sample as a graph node, we propose a subgraph-based framework with novel self-supervision tasks that can learn effective audio representations. During training, subgraphs are constructed by sampling the entire pool of available training data to exploit the relationship between the labelled and unlabeled audio samples. During inference, we use random edges to alleviate the overhead of graph construction. We evaluate our model on three benchmark audio databases, and two tasks: acoustic event detection and speech emotion recognition. Our semi-supervised model performs better or on par with fully supervised models and outperforms several competitive existing models. Our model is compact (240k parameters), and can produce generalized audio representations that are robust to different types of signal noise.