 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models for Generalization and Robustness via Data Compression
Paper and Code
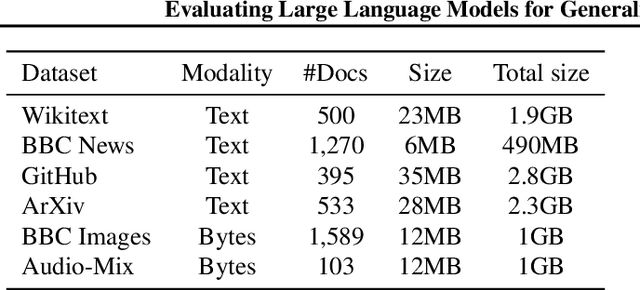
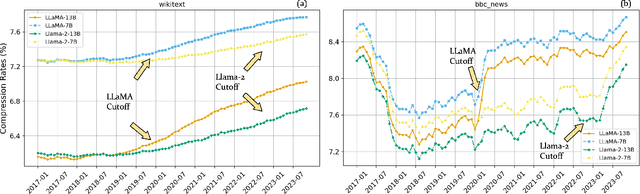
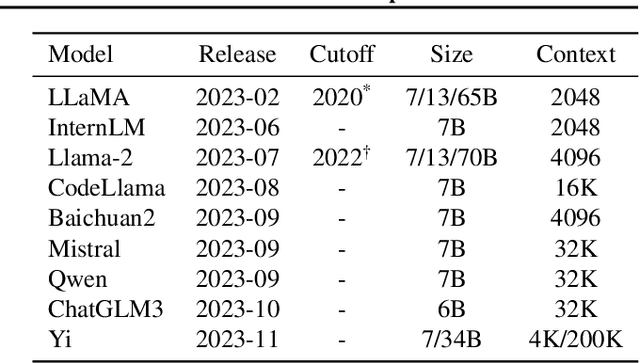
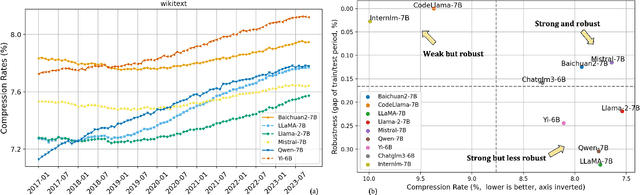
Existing methods for evaluating large language models face challenges such as data contamination, sensitivity to prompts, and the high cost of benchmark creation. To address this, we propose a lossless data compression based evaluation approach that tests how models' predictive abilities generalize after their training cutoff. Specifically, we collect comprehensive test data spanning 83 months from 2017 to 2023 and split the data into training and testing periods according to models' training data cutoff. We measure: 1) the compression performance on the testing period as a measure of generalization on unseen data; and 2) the performance gap between the training and testing period as a measure of robustness. Our experiments test 14 representative large language models with various sizes on sources including Wikipedia, news articles, code, arXiv papers, and multi-modal data. We find that the compression rate of many models reduces significantly after their cutoff date, but models such as Mistral and Llama-2 demonstrate a good balance between performance and robustness. Results also suggest that models struggle to generalize on news and code data, but work especially well on arXiv papers. We also find the context size and tokenization implementation have a big impact of on the overall compression performance.