 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Challenging Metaphors that Confuse Pretrained Language Models
Paper and Code
Jan 29, 2024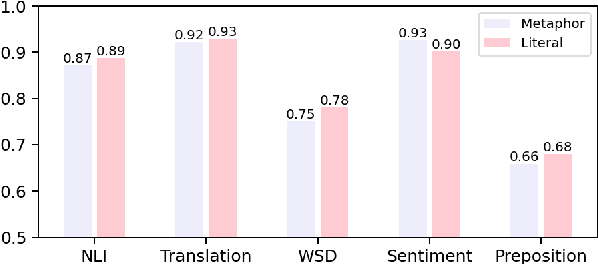

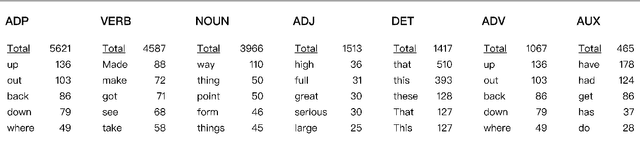
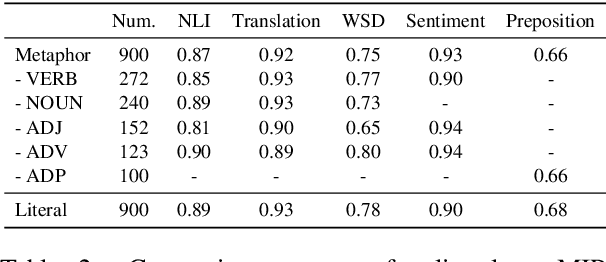
Metaphors are considered to pose challenges for a wide spectrum of NLP tasks. This gives rise to the area of computational metaphor processing. However, it remains unclear what types of metaphors challenge current state-of-the-art models. In this paper, we test various NLP models on the VUA metaphor dataset and quantify to what extent metaphors affect models' performance on various downstream tasks. Analysis reveals that VUA includes a large number of metaphors that pose little difficulty to downstream tasks. We would like to shift the attention of researchers away from these metaphors to instead focus on challenging metaphors. To identify hard metaphors, we propose an automatic pipeline that identifies metaphors that challenge a particular model. Our analysis demonstrates that our detected hard metaphors contrast significantly with VUA and reduce the accuracy of machine translation by 16\%, QA performance by 4\%, NLI by 7\%, and metaphor identification recall by over 14\% for various popular NLP systems.