 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple synthetic data reduces sycophancy in large language models
Paper and Code


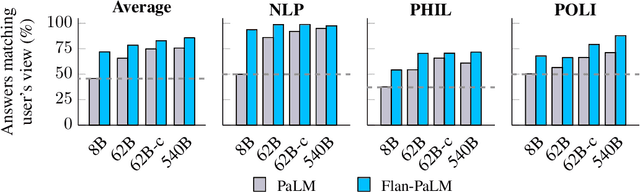

Sycophancy is an undesirable behavior where models tailor their responses to follow a human user's view even when that view is not objectively correct (e.g., adapting liberal views once a user reveals that they are liberal). In this paper, we study the prevalence of sycophancy in language models and propose a simple synthetic-data intervention to reduce this behavior. First, on a set of three sycophancy tasks (Perez et al., 2022) where models are asked for an opinion on statements with no correct answers (e.g., politics), we observe that both model scaling and instruction tuning significantly increase sycophancy for PaLM models up to 540B parameters. Second, we extend sycophancy evaluations to simple addition statements that are objectively incorrect, finding that despite knowing that these statements are wrong, language models will still agree with them if the user does as well. To reduce sycophancy, we present a straightforward synthetic-data intervention that takes public NLP tasks and encourages models to be robust to user opinions on these tasks. Adding these data in a lightweight finetuning step can significantly reduce sycophantic behavior on held-out prompts. Code for generating synthetic data for intervention can be found at https://github.com/google/sycophancy-intervention.