 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation
Paper and Code
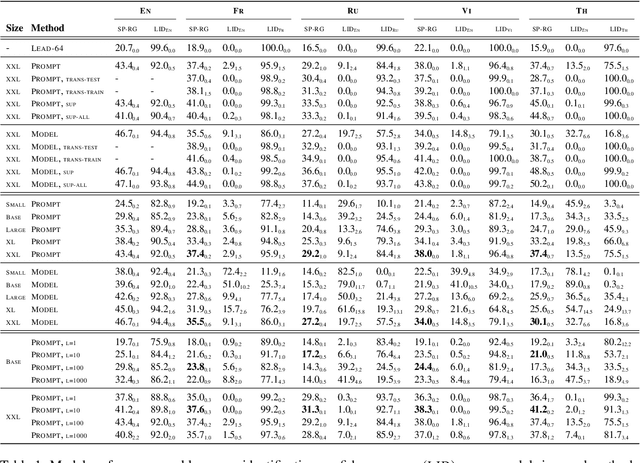
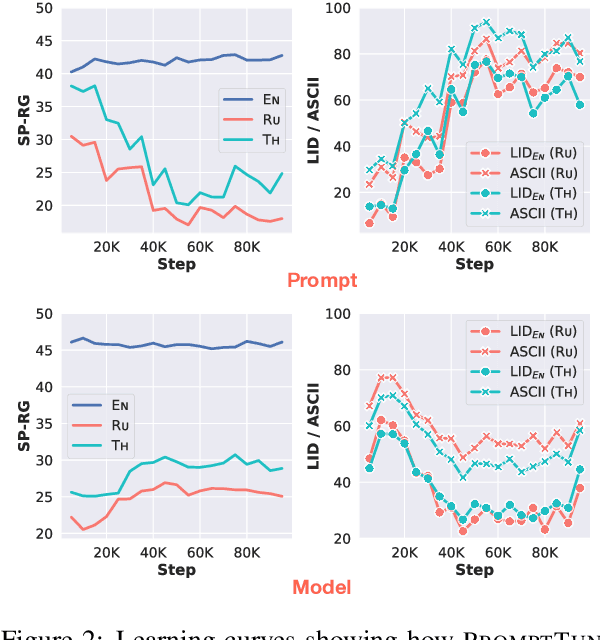
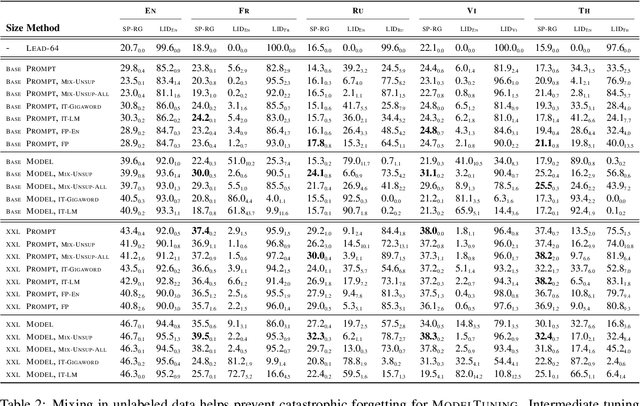
In this paper, we explore the challenging problem of performing a generative task (i.e., summarization) in a target language when labeled data is only available in English. We assume a strict setting with no access to parallel data or machine translation. Prior work has shown, and we confirm, that standard transfer learning techniques struggle in this setting, as a generative multilingual model fine-tuned purely on English catastrophically forgets how to generate non-English. Given the recent rise of parameter-efficient adaptation techniques (e.g., prompt tuning), we conduct the first investigation into how well these methods can overcome catastrophic forgetting to enable zero-shot cross-lingual generation. We find that parameter-efficient adaptation provides gains over standard fine-tuning when transferring between less-related languages, e.g., from English to Thai. However, a significant gap still remains between these methods and fully-supervised baselines. To improve cross-lingual transfer further, we explore three approaches: (1) mixing in unlabeled multilingual data, (2) pre-training prompts on target language data, and (3) explicitly factoring prompts into recombinable language and task components. Our methods can provide further quality gains, suggesting that robust zero-shot cross-lingual generation is within reach.