 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Transfer Learning for Text Diffusion Models
Jan 30, 2024In this report, we explore the potential for text diffusion to replace autoregressive (AR) decoding for the training and deployment of large language models (LLMs). We are particularly interested to see whether pretrained AR models can be transformed into text diffusion models through a lightweight adaptation procedure we call ``AR2Diff''. We begin by establishing a strong baseline setup for training text diffusion models. Comparing across multiple architectures and pretraining objectives, we find that training a decoder-only model with a prefix LM objective is best or near-best across several tasks. Building on this finding, we test various transfer learning setups for text diffusion models. On machine translation, we find that text diffusion underperforms the standard AR approach. However, on code synthesis and extractive QA, we find diffusion models trained from scratch outperform AR models in many cases. We also observe quality gains from AR2Diff -- adapting AR models to use diffusion decoding. These results are promising given that text diffusion is relatively underexplored and can be significantly faster than AR decoding for long text generation.
Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation
May 25, 2022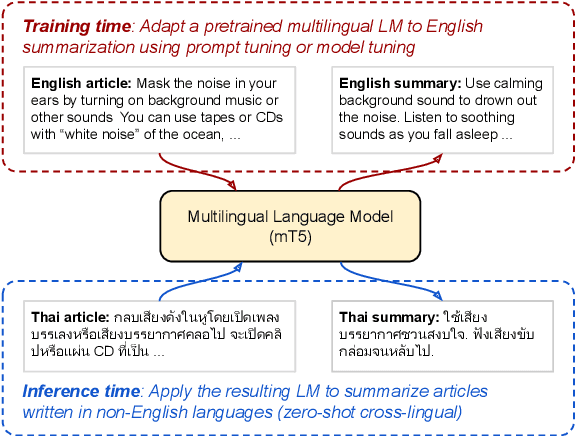
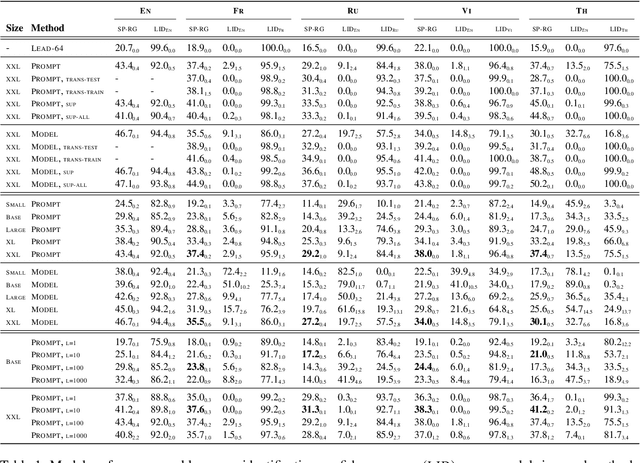
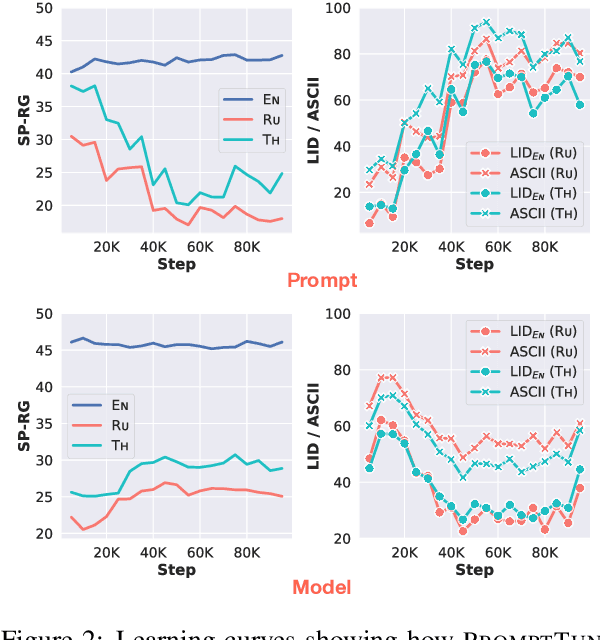
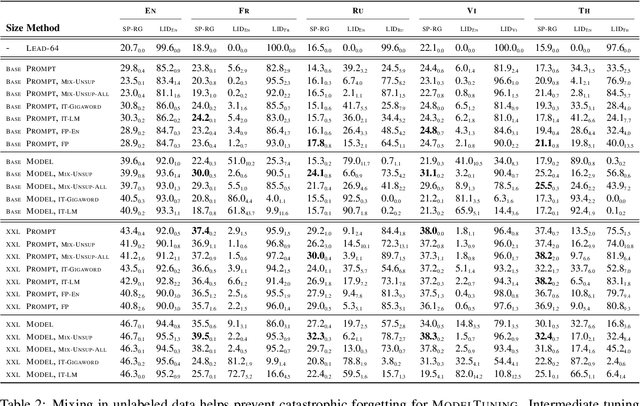
In this paper, we explore the challenging problem of performing a generative task (i.e., summarization) in a target language when labeled data is only available in English. We assume a strict setting with no access to parallel data or machine translation. Prior work has shown, and we confirm, that standard transfer learning techniques struggle in this setting, as a generative multilingual model fine-tuned purely on English catastrophically forgets how to generate non-English. Given the recent rise of parameter-efficient adaptation techniques (e.g., prompt tuning), we conduct the first investigation into how well these methods can overcome catastrophic forgetting to enable zero-shot cross-lingual generation. We find that parameter-efficient adaptation provides gains over standard fine-tuning when transferring between less-related languages, e.g., from English to Thai. However, a significant gap still remains between these methods and fully-supervised baselines. To improve cross-lingual transfer further, we explore three approaches: (1) mixing in unlabeled multilingual data, (2) pre-training prompts on target language data, and (3) explicitly factoring prompts into recombinable language and task components. Our methods can provide further quality gains, suggesting that robust zero-shot cross-lingual generation is within reach.
ByT5: Towards a token-free future with pre-trained byte-to-byte models
May 28, 2021
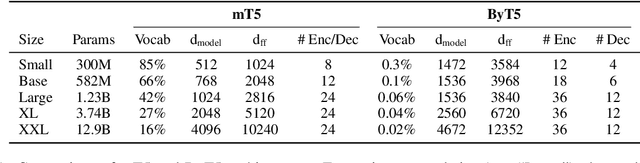
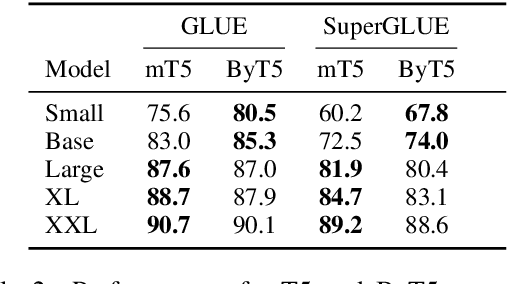
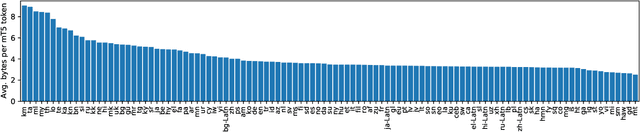
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
mT5: A massively multilingual pre-trained text-to-text transformer
Oct 23, 2020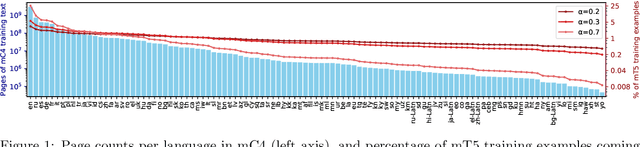


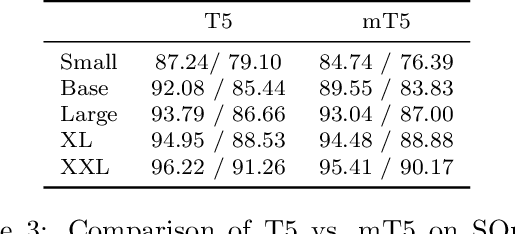
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
LAReQA: Language-agnostic answer retrieval from a multilingual pool
Apr 11, 2020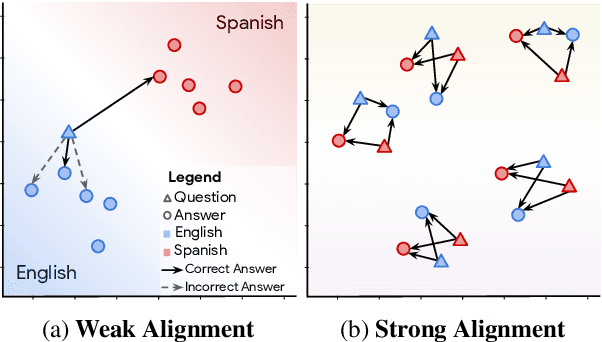
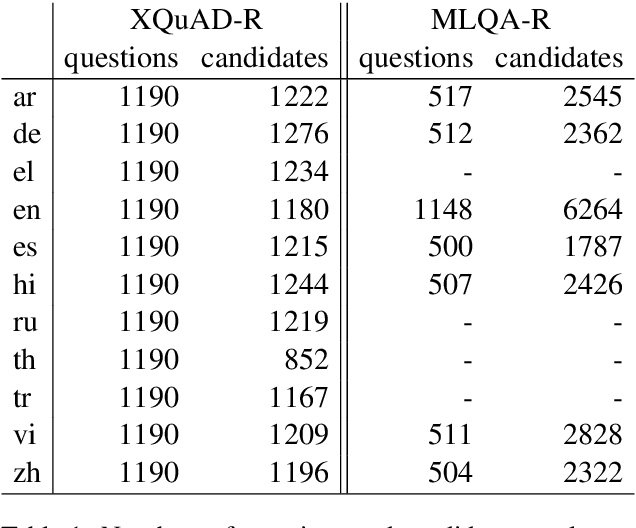

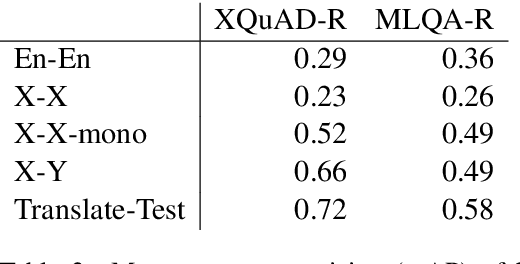
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for "strong" cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT out-of-the-box. Interestingly, the embedding baseline that performs the best on LAReQA falls short of competing baselines on zero-shot variants of our task that only target "weak" alignment. This finding underscores our claim that languageagnostic retrieval is a substantively new kind of cross-lingual evaluation.