 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAReQA: Language-agnostic answer retrieval from a multilingual pool
Apr 11, 2020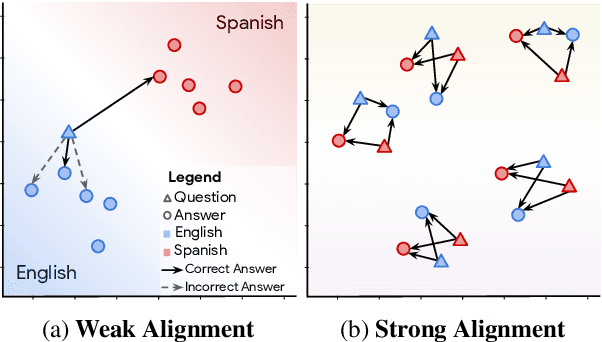
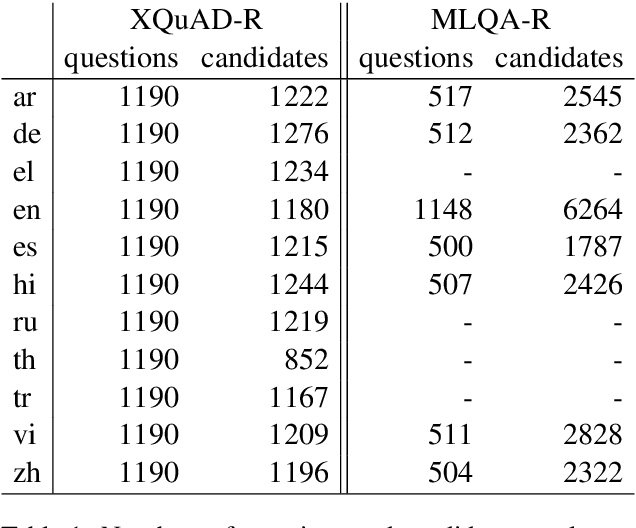

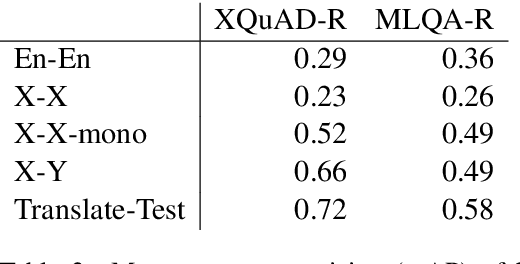
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for "strong" cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT out-of-the-box. Interestingly, the embedding baseline that performs the best on LAReQA falls short of competing baselines on zero-shot variants of our task that only target "weak" alignment. This finding underscores our claim that languageagnostic retrieval is a substantively new kind of cross-lingual evaluation.