 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Instruction Tuning
Paper and Code

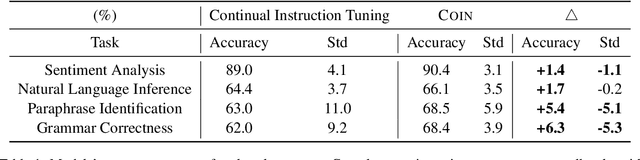
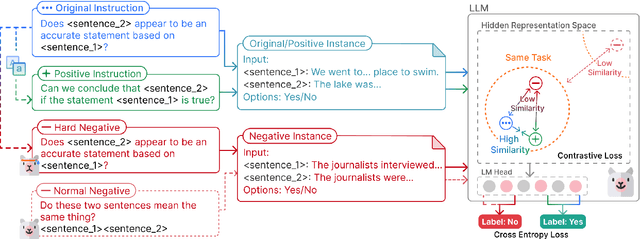
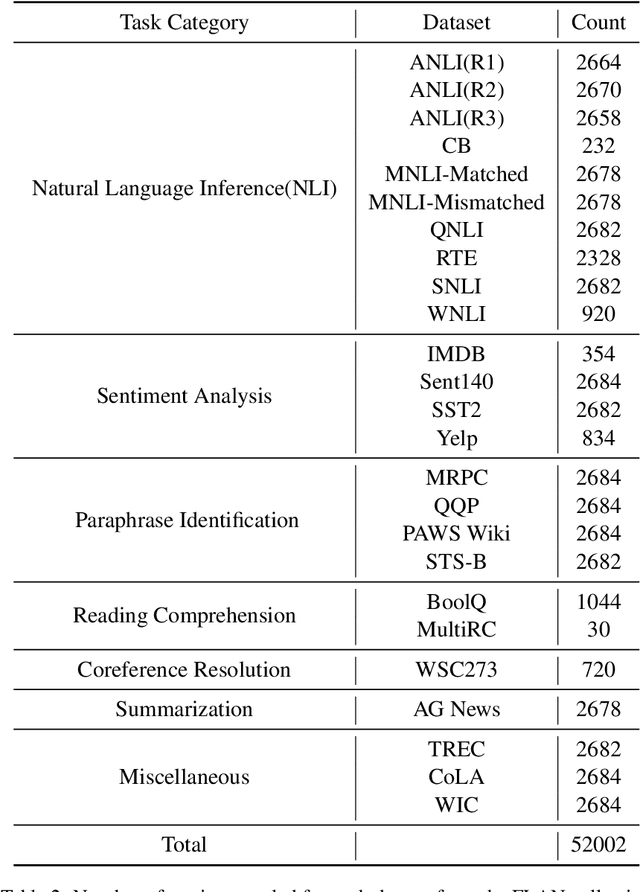
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy.