 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multitask Learning Approach for Diacritic Restoration
Jun 07, 2020
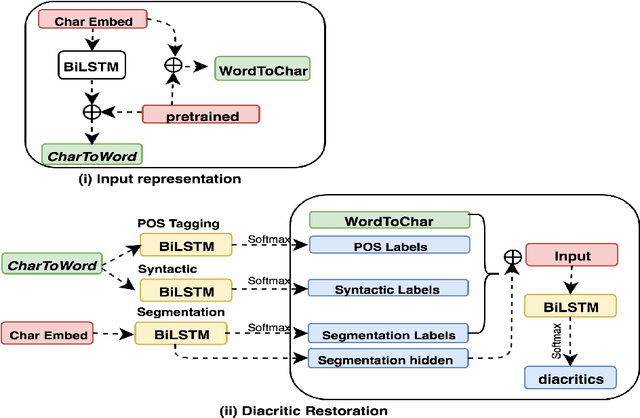
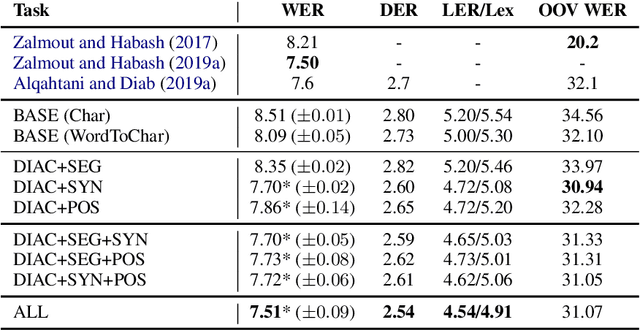
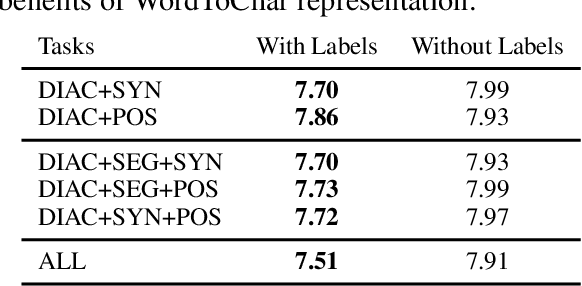
In many languages like Arabic, diacritics are used to specify pronunciations as well as meanings. Such diacritics are often omitted in written text, increasing the number of possible pronunciations and meanings for a word. This results in a more ambiguous text making computational processing on such text more difficult. Diacritic restoration is the task of restoring missing diacritics in the written text. Most state-of-the-art diacritic restoration models are built on character level information which helps generalize the model to unseen data, but presumably lose useful information at the word level. Thus, to compensate for this loss, we investigate the use of multi-task learning to jointly optimize diacritic restoration with related NLP problems namely word segmentation, part-of-speech tagging, and syntactic diacritization. We use Arabic as a case study since it has sufficient data resources for tasks that we consider in our joint modeling. Our joint models significantly outperform the baselines and are comparable to the state-of-the-art models that are more complex relying on morphological analyzers and/or a lot more data (e.g. dialectal data).
TRANS-BLSTM: Transformer with Bidirectional LSTM for Language Understanding
Mar 16, 2020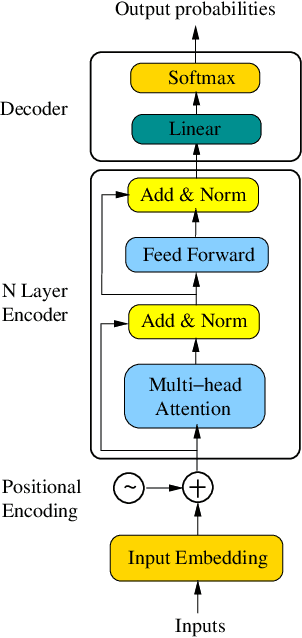

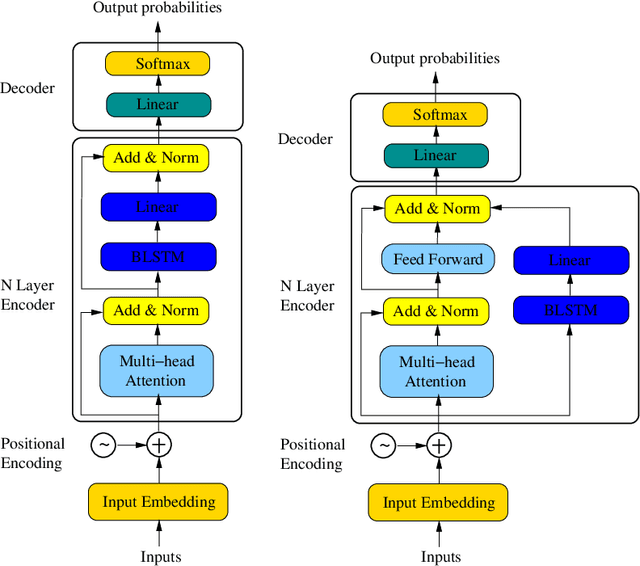

Bidirectional Encoder Representations from Transformers (BERT) has recently achieved state-of-the-art performance on a broad range of NLP tasks including sentence classification, machine translation, and question answering. The BERT model architecture is derived primarily from the transformer. Prior to the transformer era, bidirectional Long Short-Term Memory (BLSTM) has been the dominant modeling architecture for neural machine translation and question answering. In this paper, we investigate how these two modeling techniques can be combined to create a more powerful model architecture. We propose a new architecture denoted as Transformer with BLSTM (TRANS-BLSTM) which has a BLSTM layer integrated to each transformer block, leading to a joint modeling framework for transformer and BLSTM. We show that TRANS-BLSTM models consistently lead to improvements in accuracy compared to BERT baselines in GLUE and SQuAD 1.1 experiments. Our TRANS-BLSTM model obtains an F1 score of 94.01% on the SQuAD 1.1 development dataset, which is comparable to the state-of-the-art result.
Efficient Convolutional Neural Networks for Diacritic Restoration
Dec 14, 2019
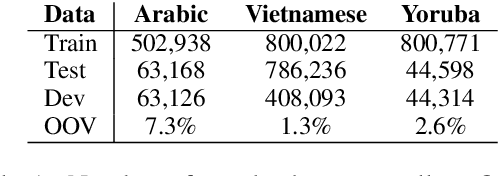
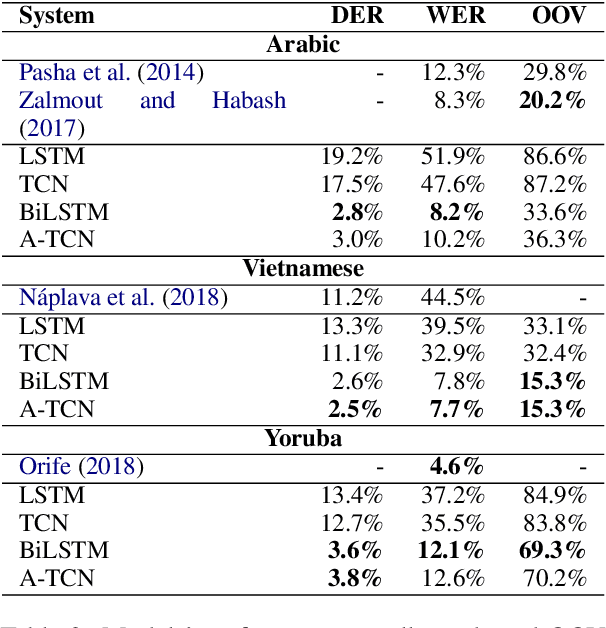
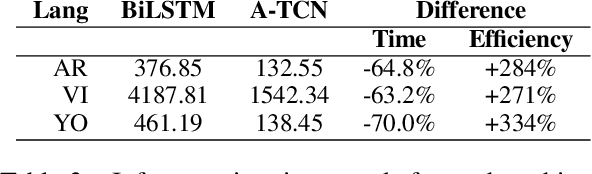
Diacritic restoration has gained importance with the growing need for machines to understand written texts. The task is typically modeled as a sequence labeling problem and currently Bidirectional Long Short Term Memory (BiLSTM) models provide state-of-the-art results. Recently, Bai et al. (2018) show the advantages of Temporal Convolutional Neural Networks (TCN) over Recurrent Neural Networks (RNN) for sequence modeling in terms of performance and computational resources. As diacritic restoration benefits from both previous as well as subsequent timesteps, we further apply and evaluate a variant of TCN, Acausal TCN (A-TCN), which incorporates context from both directions (previous and future) rather than strictly incorporating previous context as in the case of TCN. A-TCN yields significant improvement over TCN for diacritization in three different languages: Arabic, Yoruba, and Vietnamese. Furthermore, A-TCN and BiLSTM have comparable performance, making A-TCN an efficient alternative over BiLSTM since convolutions can be trained in parallel. A-TCN is significantly faster than BiLSTM at inference time (270%-334% improvement in the amount of text diacritized per minute).
* accepted in EMNLP 2019