 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Adaptive Reasoning for Monocular 3D Multi-Person Pose Estimation
Paper and Code
Jul 16, 2022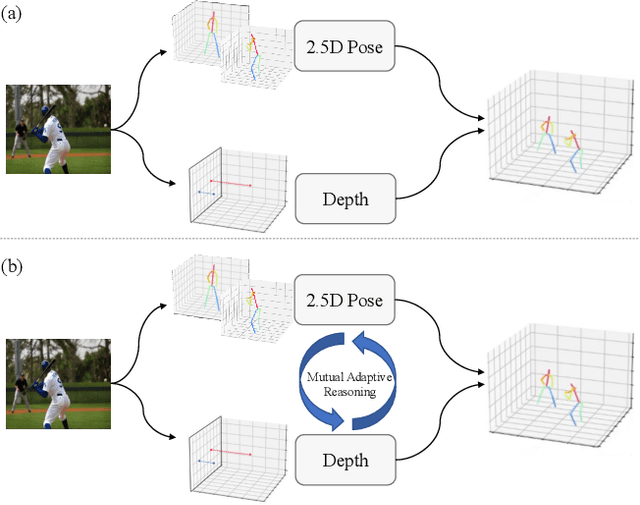
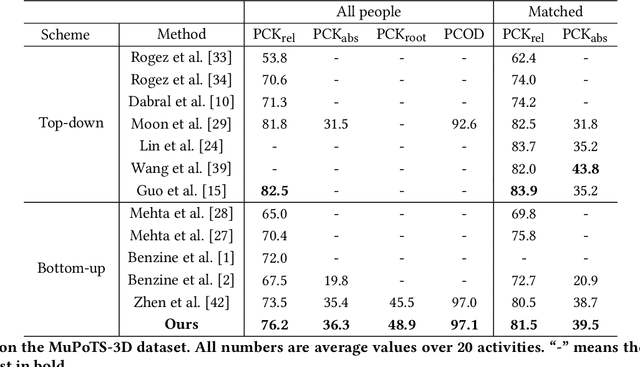
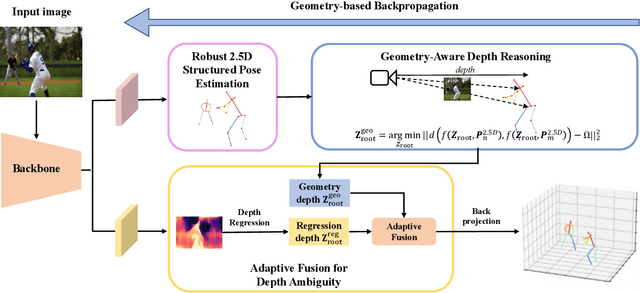
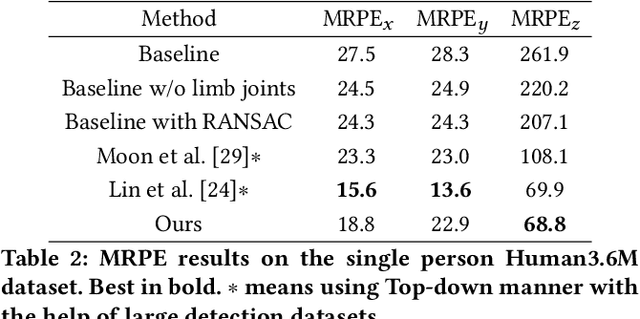
Inter-person occlusion and depth ambiguity make estimating the 3D poses of monocular multiple persons as camera-centric coordinates a challenging problem. Typical top-down frameworks suffer from high computational redundancy with an additional detection stage. By contrast, the bottom-up methods enjoy low computational costs as they are less affected by the number of humans. However, most existing bottom-up methods treat camera-centric 3D human pose estimation as two unrelated subtasks: 2.5D pose estimation and camera-centric depth estimation. In this paper, we propose a unified model that leverages the mutual benefits of both these subtasks. Within the framework, a robust structured 2.5D pose estimation is designed to recognize inter-person occlusion based on depth relationships. Additionally, we develop an end-to-end geometry-aware depth reasoning method that exploits the mutual benefits of both 2.5D pose and camera-centric root depths. This method first uses 2.5D pose and geometry information to infer camera-centric root depths in a forward pass, and then exploits the root depths to further improve representation learning of 2.5D pose estimation in a backward pass. Further, we designed an adaptive fusion scheme that leverages both visual perception and body geometry to alleviate inherent depth ambiguity issues. Extensive experiments demonstrate the superiority of our proposed model over a wide range of bottom-up methods. Our accuracy is even competitive with top-down counterparts. Notably, our model runs much faster than existing bottom-up and top-down methods.