 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Than Ground-truth? Beyond Supervised Learning for Photoacoustic Imaging Reconstruction
Paper and Code

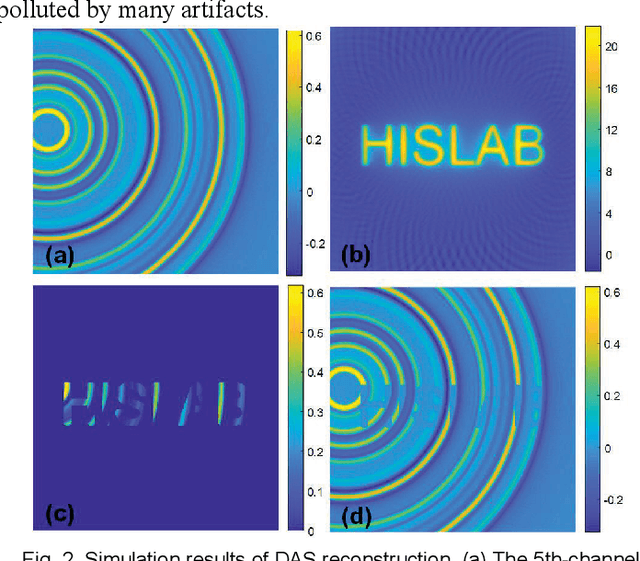
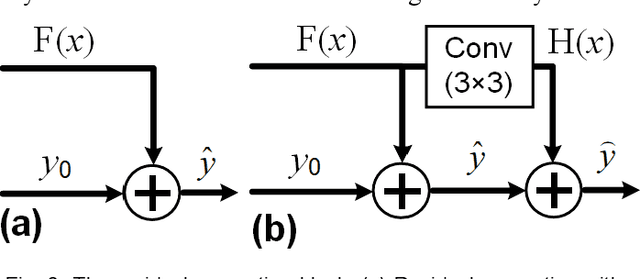
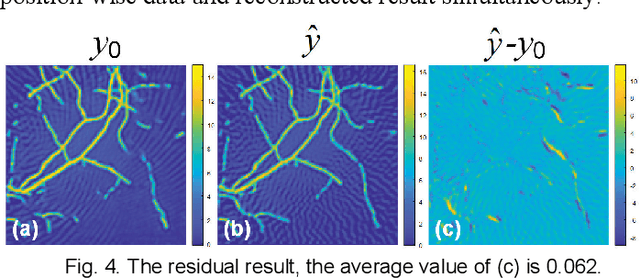
Photoacoustic computed tomography (PACT) reconstructs the initial pressure distribution from raw PA signals. Standard reconstruction always induces artifacts using limited-view signals, which are influenced by limited angle coverage of transducers, finite bandwidth, and uncertain heterogeneous biological tissue. Recently, supervised deep learning has been used to overcome limited-view problem that requires ground-truth. However, even full-view sampling still induces artifacts that cannot be used to train the model. It causes a dilemma that we could not acquire perfect ground-truth in practice. To reduce the dependence on the quality of ground-truth, in this paper, for the first time, we propose a beyond supervised reconstruction framework (BSR-Net) based on deep learning to compensate the limited-view issue by feeding limited-view position-wise data. A quarter position-wise data is fed into model and outputs a group full-view data. Specifically, our method introduces a residual structure, which generates beyond supervised reconstruction result, whose artifacts are drastically reduced in the output compared to ground-truth. Moreover, two novel losses are designed to restrain the artifacts. The numerical and in-vivo results have demonstrated the performance of our method to reconstruct the full-view image without artifacts.