 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Discriminative Relational Features for Sequence Labeling
Paper and Code
May 07, 2017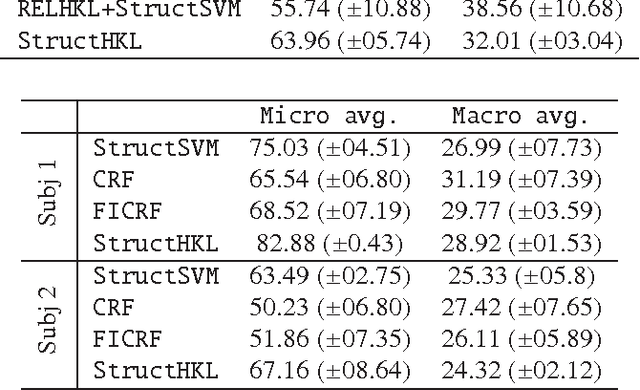
Discovering relational structure between input features in sequence labeling models has shown to improve their accuracy in several problem settings. However, the search space of relational features is exponential in the number of basic input features. Consequently, approaches that learn relational features, tend to follow a greedy search strategy. In this paper, we study the possibility of optimally learning and applying discriminative relational features for sequence labeling. For learning features derived from inputs at a particular sequence position, we propose a Hierarchical Kernels-based approach (referred to as Hierarchical Kernel Learning for Structured Output Spaces - StructHKL). This approach optimally and efficiently explores the hierarchical structure of the feature space for problems with structured output spaces such as sequence labeling. Since the StructHKL approach has limitations in learning complex relational features derived from inputs at relative positions, we propose two solutions to learn relational features namely, (i) enumerating simple component features of complex relational features and discovering their compositions using StructHKL and (ii) leveraging relational kernels, that compute the similarity between instances implicitly, in the sequence labeling problem. We perform extensive empirical evaluation on publicly available datasets and record our observations on settings in which certain approaches are effective.