 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAeroPlace-Flow: Language-Grounded Object Placement for Aerial Manipulators via Visual Foresight and Object Flow
Mar 08, 2026Precise object placement remains underexplored in aerial manipulation, where most systems rely on predefined target coordinates and focus primarily on grasping and control. Specifying exact placement poses, however, is cumbersome in real-world settings, where users naturally communicate goals through language. In this work, we present AeroPlace-Flow, a training-free framework for language-grounded aerial object placement that unifies visual foresight with explicit 3D geometric reasoning and object flow. Given RGB-D observations of the object and the placement scene, along with a natural language instruction, AeroPlace-Flow first synthesizes a task-complete goal image using image editing models. The imagined configuration is then grounded into metric 3D space through depth alignment and object-centric reasoning, enabling the inference of a collision-aware object flow that transports the grasped object to a language and contact-consistent placement configuration. The resulting motion is executed via standard trajectory tracking for an aerial manipulator. AeroPlace-Flow produces executable placement targets without requiring predefined poses or task-specific training. We validate our approach through extensive simulation and real-world experiments, demonstrating reliable language-conditioned placement across diverse aerial scenarios with an average success rate of 75% on hardware.
Individual Treatment Effect Estimation Through Controlled Neural Network Training in Two Stages
Jan 21, 2022We develop a Causal-Deep Neural Network (CDNN) model trained in two stages to infer causal impact estimates at an individual unit level. Using only the pre-treatment features in stage 1 in the absence of any treatment information, we learn an encoding for the covariates that best represents the outcome. In the $2^{nd}$ stage we further seek to predict the unexplained outcome from stage 1, by introducing the treatment indicator variables alongside the encoded covariates. We prove that even without explicitly computing the treatment residual, our method still satisfies the desirable local Neyman orthogonality, making it robust to small perturbations in the nuisance parameters. Furthermore, by establishing connections with the representation learning approaches, we create a framework from which multiple variants of our algorithm can be derived. We perform initial experiments on the publicly available data sets to compare these variants and get guidance in selecting the best variant of our CDNN method. On evaluating CDNN against the state-of-the-art approaches on three benchmarking datasets, we observe that CDNN is highly competitive and often yields the most accurate individual treatment effect estimates. We highlight the strong merits of CDNN in terms of its extensibility to multiple use cases.
Learning Discriminative Relational Features for Sequence Labeling
May 07, 2017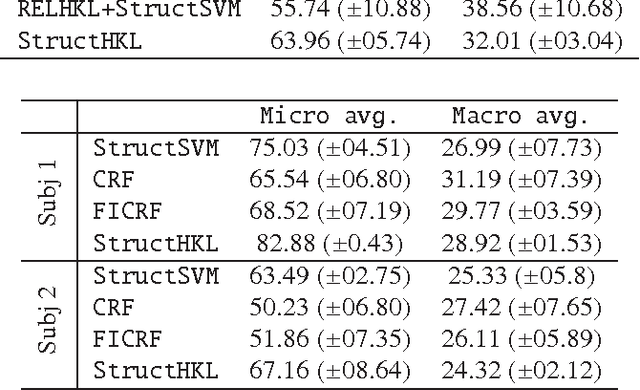
Discovering relational structure between input features in sequence labeling models has shown to improve their accuracy in several problem settings. However, the search space of relational features is exponential in the number of basic input features. Consequently, approaches that learn relational features, tend to follow a greedy search strategy. In this paper, we study the possibility of optimally learning and applying discriminative relational features for sequence labeling. For learning features derived from inputs at a particular sequence position, we propose a Hierarchical Kernels-based approach (referred to as Hierarchical Kernel Learning for Structured Output Spaces - StructHKL). This approach optimally and efficiently explores the hierarchical structure of the feature space for problems with structured output spaces such as sequence labeling. Since the StructHKL approach has limitations in learning complex relational features derived from inputs at relative positions, we propose two solutions to learn relational features namely, (i) enumerating simple component features of complex relational features and discovering their compositions using StructHKL and (ii) leveraging relational kernels, that compute the similarity between instances implicitly, in the sequence labeling problem. We perform extensive empirical evaluation on publicly available datasets and record our observations on settings in which certain approaches are effective.