 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Music Genre Classification through Multi-Algorithm Analysis and User-Friendly Visualization
May 27, 2024



The aim of this study is to teach an algorithm how to recognize different types of music. Users will submit songs for analysis. Since the algorithm hasn't heard these songs before, it needs to figure out what makes each song unique. It does this by breaking down the songs into different parts and studying things like rhythm, melody, and tone via supervised learning because the program learns from examples that are already labelled. One important thing to consider when classifying music is its genre, which can be quite complex. To ensure accuracy, we use five different algorithms, each working independently, to analyze the songs. This helps us get a more complete understanding of each song's characteristics. Therefore, our goal is to correctly identify the genre of each submitted song. Once the analysis is done, the results are presented using a graphing tool, making it easy for users to understand and provide feedback.
A Novel Audio Representation for Music Genre Identification in MIR
Apr 01, 2024



For Music Information Retrieval downstream tasks, the most common audio representation is time-frequency-based, such as Mel spectrograms. In order to identify musical genres, this study explores the possibilities of a new form of audio representation one of the most usual MIR downstream tasks. Therefore, to discretely encoding music using deep vector quantization; a novel audio representation was created for the innovative generative music model i.e. Jukebox. The effectiveness of Jukebox's audio representation is compared to Mel spectrograms using a dataset that is almost equivalent to State-of-the-Art (SOTA) and an almost same transformer design. The results of this study imply that, at least when the transformers are pretrained using a very modest dataset of 20k tracks, Jukebox's audio representation is not superior to Mel spectrograms. This could be explained by the fact that Jukebox's audio representation does not sufficiently take into account the peculiarities of human hearing perception. On the other hand, Mel spectrograms are specifically created with the human auditory sense in mind.
Unveiling the Impact of Macroeconomic Policies: A Double Machine Learning Approach to Analyzing Interest Rate Effects on Financial Markets
Mar 31, 2024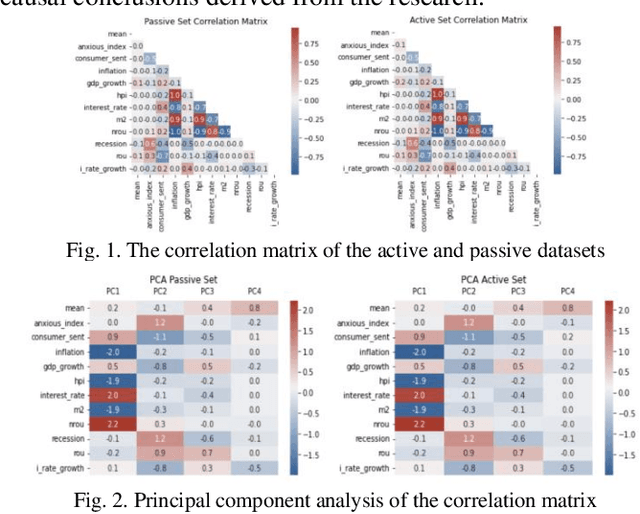
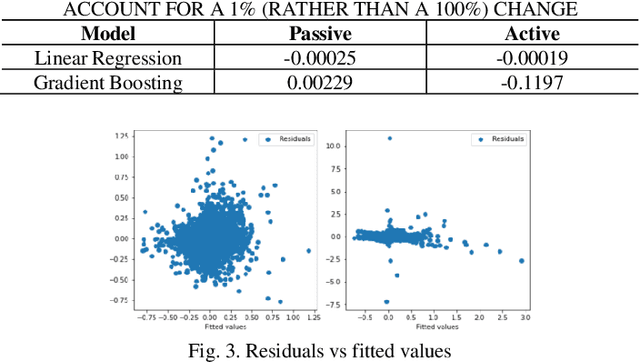
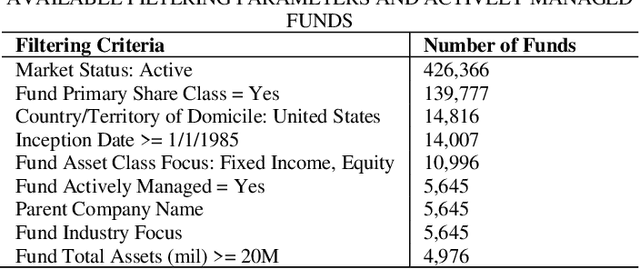
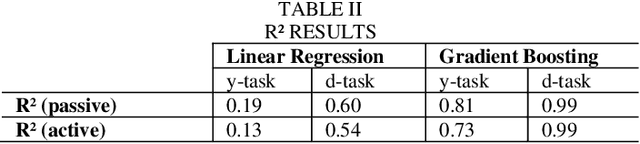
This study examines the effects of macroeconomic policies on financial markets using a novel approach that combines Machine Learning (ML) techniques and causal inference. It focuses on the effect of interest rate changes made by the US Federal Reserve System (FRS) on the returns of fixed income and equity funds between January 1986 and December 2021. The analysis makes a distinction between actively and passively managed funds, hypothesizing that the latter are less susceptible to changes in interest rates. The study contrasts gradient boosting and linear regression models using the Double Machine Learning (DML) framework, which supports a variety of statistical learning techniques. Results indicate that gradient boosting is a useful tool for predicting fund returns; for example, a 1% increase in interest rates causes an actively managed fund's return to decrease by -11.97%. This understanding of the relationship between interest rates and fund performance provides opportunities for additional research and insightful, data-driven advice for fund managers and investors
The Emotional Impact of Game Duration: A Framework for Understanding Player Emotions in Extended Gameplay Sessions
Mar 31, 2024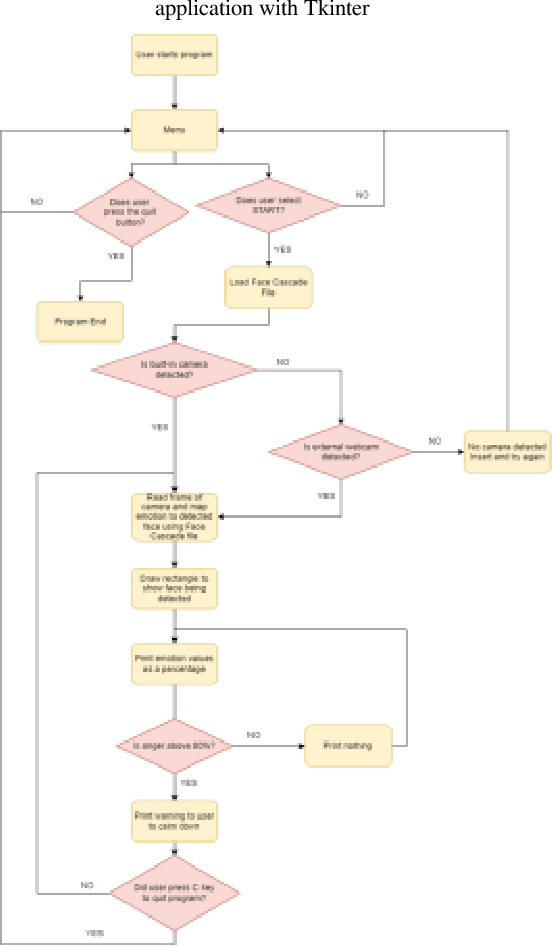
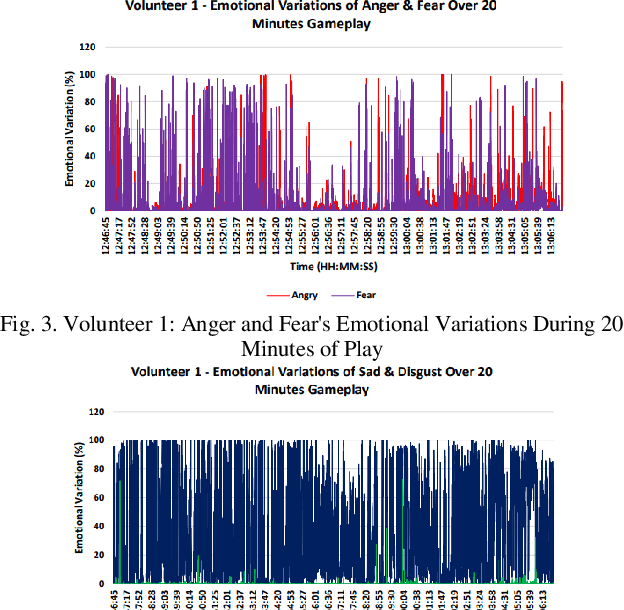
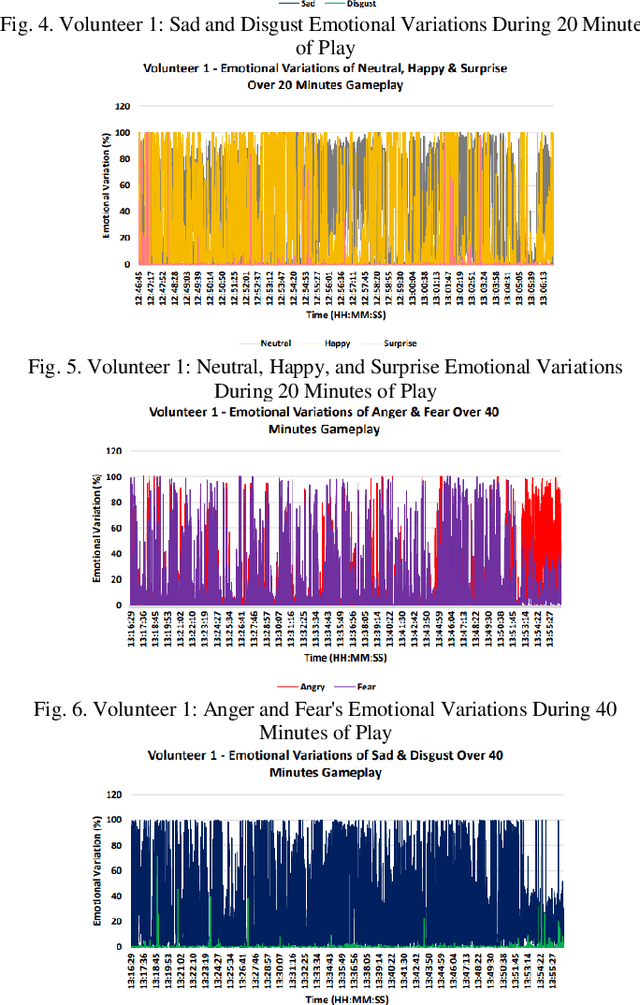
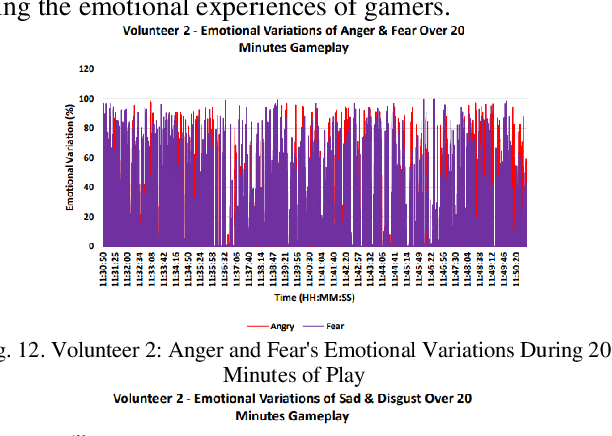
Video games have played a crucial role in entertainment since their development in the 1970s, becoming even more prominent during the lockdown period when people were looking for ways to entertain them. However, at that time, players were unaware of the significant impact that playtime could have on their feelings. This has made it challenging for designers and developers to create new games since they have to control the emotional impact that these games will take on players. Thus, the purpose of this study is to look at how a player's emotions are affected by the duration of the game. In order to achieve this goal, a framework for emotion detection is created. According to the experiment's results, the volunteers' general ability to express emotions increased from 20 to 60 minutes. In comparison to shorter gameplay sessions, the experiment found that extended gameplay sessions did significantly affect the player's emotions. According to the results, it was recommended that in order to lessen the potential emotional impact that playing computer and video games may have in the future, game producers should think about creating shorter, entertaining games.
Advancing Audio Fingerprinting Accuracy Addressing Background Noise and Distortion Challenges
Feb 21, 2024
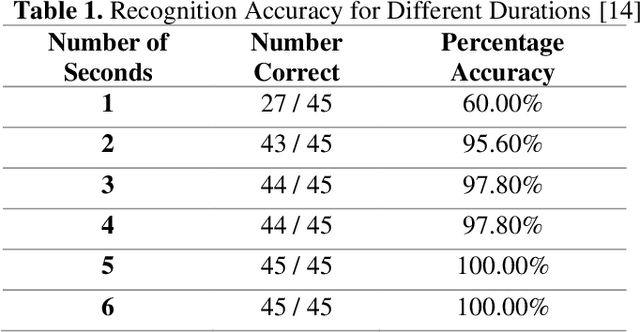
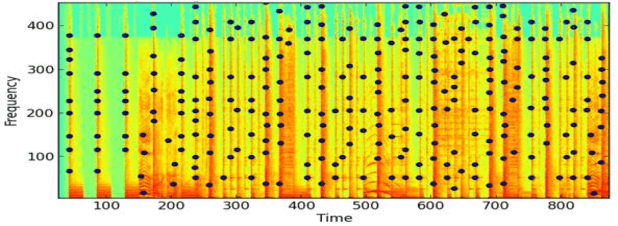
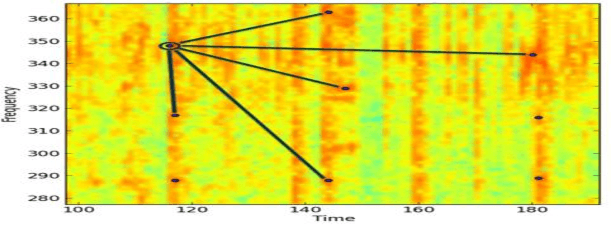
Audio fingerprinting, exemplified by pioneers like Shazam, has transformed digital audio recognition. However, existing systems struggle with accuracy in challenging conditions, limiting broad applicability. This research proposes an AI and ML integrated audio fingerprinting algorithm to enhance accuracy. Built on the Dejavu Project's foundations, the study emphasizes real-world scenario simulations with diverse background noises and distortions. Signal processing, central to Dejavu's model, includes the Fast Fourier Transform, spectrograms, and peak extraction. The "constellation" concept and fingerprint hashing enable unique song identification. Performance evaluation attests to 100% accuracy within a 5-second audio input, with a system showcasing predictable matching speed for efficiency. Storage analysis highlights the critical space-speed trade-off for practical implementation. This research advances audio fingerprinting's adaptability, addressing challenges in varied environments and applications.
Enhancing End-to-End Multi-Task Dialogue Systems: A Study on Intrinsic Motivation Reinforcement Learning Algorithms for Improved Training and Adaptability
Jan 31, 2024End-to-end multi-task dialogue systems are usually designed with separate modules for the dialogue pipeline. Among these, the policy module is essential for deciding what to do in response to user input. This policy is trained by reinforcement learning algorithms by taking advantage of an environment in which an agent receives feedback in the form of a reward signal. The current dialogue systems, however, only provide meagre and simplistic rewards. Investigating intrinsic motivation reinforcement learning algorithms is the goal of this study. Through this, the agent can quickly accelerate training and improve its capacity to judge the quality of its actions by teaching it an internal incentive system. In particular, we adapt techniques for random network distillation and curiosity-driven reinforcement learning to measure the frequency of state visits and encourage exploration by using semantic similarity between utterances. Experimental results on MultiWOZ, a heterogeneous dataset, show that intrinsic motivation-based debate systems outperform policies that depend on extrinsic incentives. By adopting random network distillation, for example, which is trained using semantic similarity between user-system dialogues, an astounding average success rate of 73% is achieved. This is a significant improvement over the baseline Proximal Policy Optimization (PPO), which has an average success rate of 60%. In addition, performance indicators such as booking rates and completion rates show a 10% rise over the baseline. Furthermore, these intrinsic incentive models help improve the system's policy's resilience in an increasing amount of domains. This implies that they could be useful in scaling up to settings that cover a wider range of domains.