 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Household Robotics: Deep Interactive Reinforcement Learning for Efficient Training and Enhanced Performance
May 29, 2024
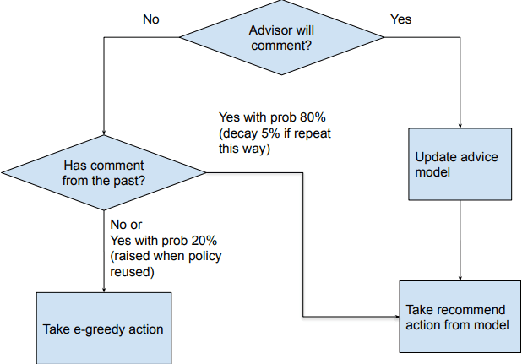


The market for domestic robots made to perform household chores is growing as these robots relieve people of everyday responsibilities. Domestic robots are generally welcomed for their role in easing human labor, in contrast to industrial robots, which are frequently criticized for displacing human workers. But before these robots can carry out domestic chores, they need to become proficient in several minor activities, such as recognizing their surroundings, making decisions, and picking up on human behaviors. Reinforcement learning, or RL, has emerged as a key robotics technology that enables robots to interact with their environment and learn how to optimize their actions to maximize rewards. However, the goal of Deep Reinforcement Learning is to address more complicated, continuous action-state spaces in real-world settings by combining RL with Neural Networks. The efficacy of DeepRL can be further augmented through interactive feedback, in which a trainer offers real-time guidance to expedite the robot's learning process. Nevertheless, the current methods have drawbacks, namely the transient application of guidance that results in repeated learning under identical conditions. Therefore, we present a novel method to preserve and reuse information and advice via Deep Interactive Reinforcement Learning, which utilizes a persistent rule-based system. This method not only expedites the training process but also lessens the number of repetitions that instructors will have to carry out. This study has the potential to advance the development of household robots and improve their effectiveness and efficiency as learners.
A Novel Audio Representation for Music Genre Identification in MIR
Apr 01, 2024



For Music Information Retrieval downstream tasks, the most common audio representation is time-frequency-based, such as Mel spectrograms. In order to identify musical genres, this study explores the possibilities of a new form of audio representation one of the most usual MIR downstream tasks. Therefore, to discretely encoding music using deep vector quantization; a novel audio representation was created for the innovative generative music model i.e. Jukebox. The effectiveness of Jukebox's audio representation is compared to Mel spectrograms using a dataset that is almost equivalent to State-of-the-Art (SOTA) and an almost same transformer design. The results of this study imply that, at least when the transformers are pretrained using a very modest dataset of 20k tracks, Jukebox's audio representation is not superior to Mel spectrograms. This could be explained by the fact that Jukebox's audio representation does not sufficiently take into account the peculiarities of human hearing perception. On the other hand, Mel spectrograms are specifically created with the human auditory sense in mind.