 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Audio Representation for Music Genre Identification in MIR
Apr 01, 2024



For Music Information Retrieval downstream tasks, the most common audio representation is time-frequency-based, such as Mel spectrograms. In order to identify musical genres, this study explores the possibilities of a new form of audio representation one of the most usual MIR downstream tasks. Therefore, to discretely encoding music using deep vector quantization; a novel audio representation was created for the innovative generative music model i.e. Jukebox. The effectiveness of Jukebox's audio representation is compared to Mel spectrograms using a dataset that is almost equivalent to State-of-the-Art (SOTA) and an almost same transformer design. The results of this study imply that, at least when the transformers are pretrained using a very modest dataset of 20k tracks, Jukebox's audio representation is not superior to Mel spectrograms. This could be explained by the fact that Jukebox's audio representation does not sufficiently take into account the peculiarities of human hearing perception. On the other hand, Mel spectrograms are specifically created with the human auditory sense in mind.
Cause and Effect: Can Large Language Models Truly Understand Causality?
Feb 28, 2024



With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
Multilevel profiling of situation and dialogue-based deep networks for movie genre classification using movie trailers
Sep 14, 2021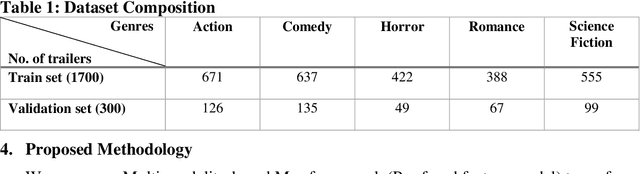
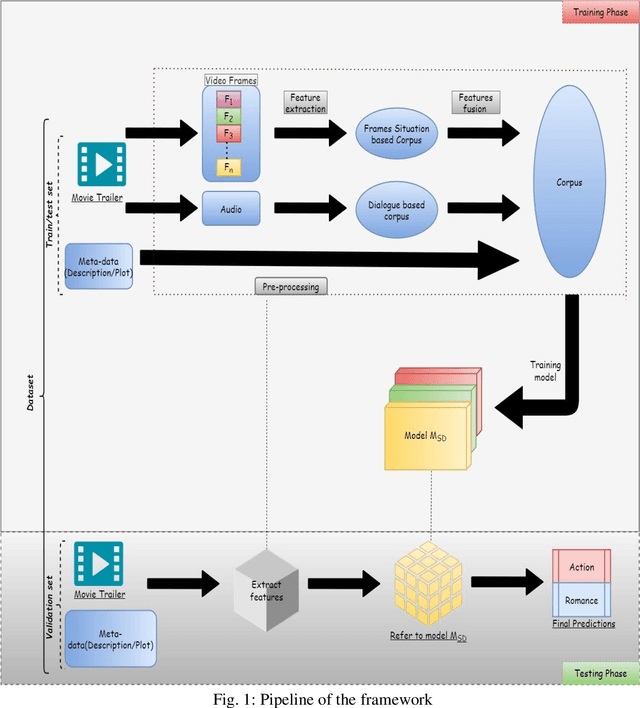
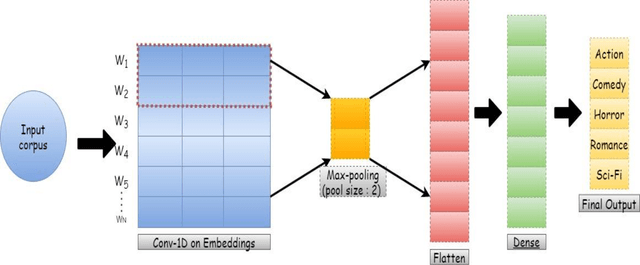
Automated movie genre classification has emerged as an active and essential area of research and exploration. Short duration movie trailers provide useful insights about the movie as video content consists of the cognitive and the affective level features. Previous approaches were focused upon either cognitive or affective content analysis. In this paper, we propose a novel multi-modality: situation, dialogue, and metadata-based movie genre classification framework that takes both cognition and affect-based features into consideration. A pre-features fusion-based framework that takes into account: situation-based features from a regular snapshot of a trailer that includes nouns and verbs providing the useful affect-based mapping with the corresponding genres, dialogue (speech) based feature from audio, metadata which together provides the relevant information for cognitive and affect based video analysis. We also develop the English movie trailer dataset (EMTD), which contains 2000 Hollywood movie trailers belonging to five popular genres: Action, Romance, Comedy, Horror, and Science Fiction, and perform cross-validation on the standard LMTD-9 dataset for validating the proposed framework. The results demonstrate that the proposed methodology for movie genre classification has performed excellently as depicted by the F1 scores, precision, recall, and area under the precision-recall curves.