 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel profiling of situation and dialogue-based deep networks for movie genre classification using movie trailers
Sep 14, 2021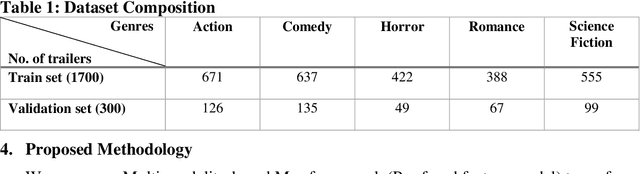
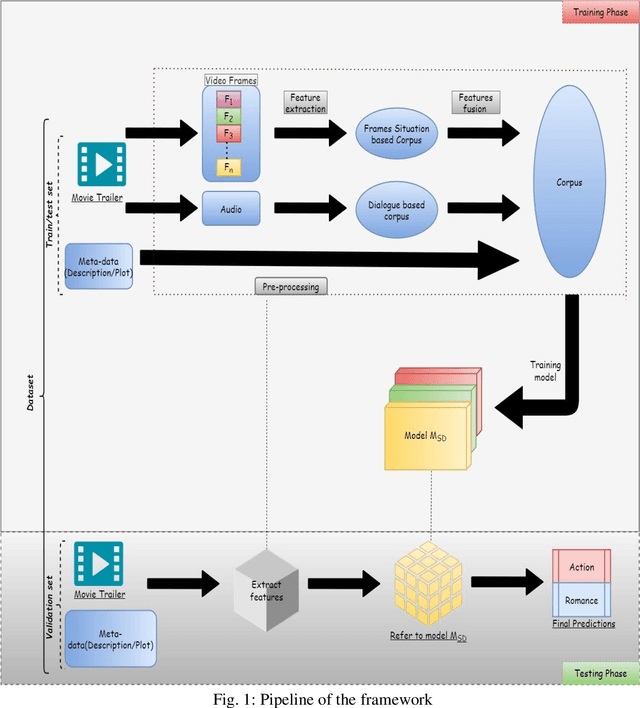
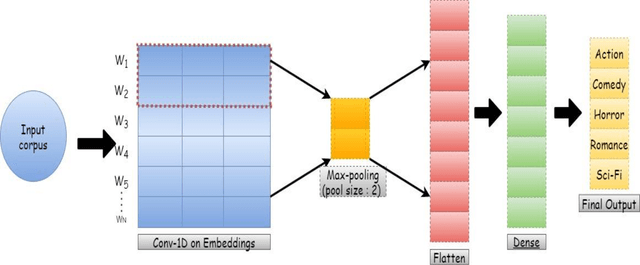
Automated movie genre classification has emerged as an active and essential area of research and exploration. Short duration movie trailers provide useful insights about the movie as video content consists of the cognitive and the affective level features. Previous approaches were focused upon either cognitive or affective content analysis. In this paper, we propose a novel multi-modality: situation, dialogue, and metadata-based movie genre classification framework that takes both cognition and affect-based features into consideration. A pre-features fusion-based framework that takes into account: situation-based features from a regular snapshot of a trailer that includes nouns and verbs providing the useful affect-based mapping with the corresponding genres, dialogue (speech) based feature from audio, metadata which together provides the relevant information for cognitive and affect based video analysis. We also develop the English movie trailer dataset (EMTD), which contains 2000 Hollywood movie trailers belonging to five popular genres: Action, Romance, Comedy, Horror, and Science Fiction, and perform cross-validation on the standard LMTD-9 dataset for validating the proposed framework. The results demonstrate that the proposed methodology for movie genre classification has performed excellently as depicted by the F1 scores, precision, recall, and area under the precision-recall curves.
Unsupervised Domain Adaptation in the Wild: Dealing with Asymmetric Label Sets
Mar 26, 2016



The goal of domain adaptation is to adapt models learned on a source domain to a particular target domain. Most methods for unsupervised domain adaptation proposed in the literature to date, assume that the set of classes present in the target domain is identical to the set of classes present in the source domain. This is a restrictive assumption that limits the practical applicability of unsupervised domain adaptation techniques in real world settings ("in the wild"). Therefore, we relax this constraint and propose a technique that allows the set of target classes to be a subset of the source classes. This way, large publicly available annotated datasets with a wide variety of classes can be used as source, even if the actual set of classes in target can be more limited and, maybe most importantly, unknown beforehand. To this end, we propose an algorithm that orders a set of source subspaces that are relevant to the target classification problem. Our method then chooses a restricted set from this ordered set of source subspaces. As an extension, even starting from multiple source datasets with varied sets of categories, this method automatically selects an appropriate subset of source categories relevant to a target dataset. Empirical analysis on a number of source and target domain datasets shows that restricting the source subspace to only a subset of categories does indeed substantially improve the eventual target classification accuracy over the baseline that considers all source classes.