 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Audio Fingerprinting Accuracy Addressing Background Noise and Distortion Challenges
Feb 21, 2024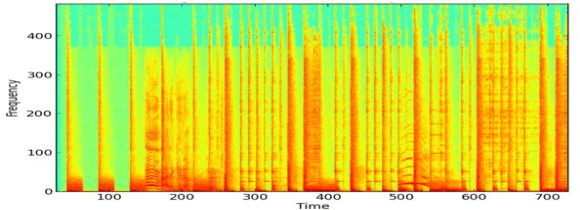
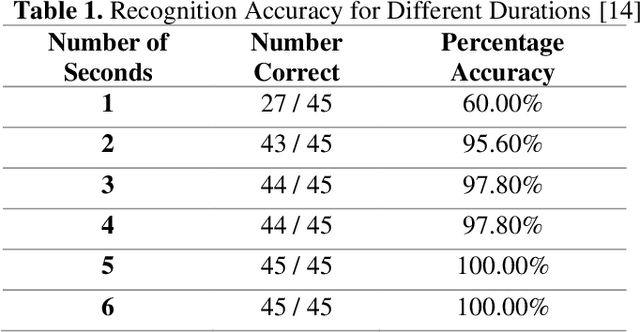
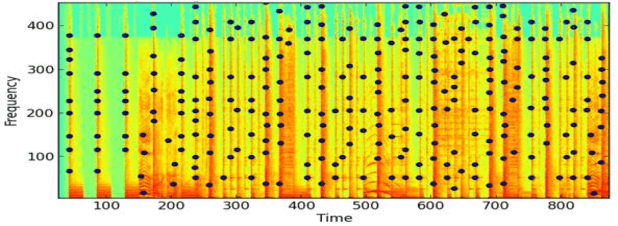
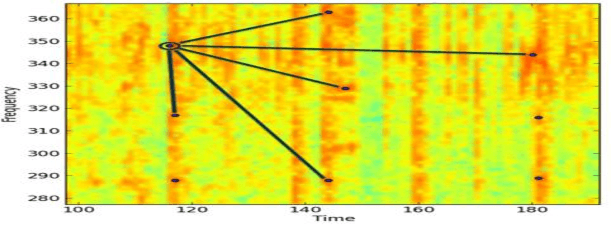
Audio fingerprinting, exemplified by pioneers like Shazam, has transformed digital audio recognition. However, existing systems struggle with accuracy in challenging conditions, limiting broad applicability. This research proposes an AI and ML integrated audio fingerprinting algorithm to enhance accuracy. Built on the Dejavu Project's foundations, the study emphasizes real-world scenario simulations with diverse background noises and distortions. Signal processing, central to Dejavu's model, includes the Fast Fourier Transform, spectrograms, and peak extraction. The "constellation" concept and fingerprint hashing enable unique song identification. Performance evaluation attests to 100% accuracy within a 5-second audio input, with a system showcasing predictable matching speed for efficiency. Storage analysis highlights the critical space-speed trade-off for practical implementation. This research advances audio fingerprinting's adaptability, addressing challenges in varied environments and applications.
Enhancing End-to-End Multi-Task Dialogue Systems: A Study on Intrinsic Motivation Reinforcement Learning Algorithms for Improved Training and Adaptability
Jan 31, 2024End-to-end multi-task dialogue systems are usually designed with separate modules for the dialogue pipeline. Among these, the policy module is essential for deciding what to do in response to user input. This policy is trained by reinforcement learning algorithms by taking advantage of an environment in which an agent receives feedback in the form of a reward signal. The current dialogue systems, however, only provide meagre and simplistic rewards. Investigating intrinsic motivation reinforcement learning algorithms is the goal of this study. Through this, the agent can quickly accelerate training and improve its capacity to judge the quality of its actions by teaching it an internal incentive system. In particular, we adapt techniques for random network distillation and curiosity-driven reinforcement learning to measure the frequency of state visits and encourage exploration by using semantic similarity between utterances. Experimental results on MultiWOZ, a heterogeneous dataset, show that intrinsic motivation-based debate systems outperform policies that depend on extrinsic incentives. By adopting random network distillation, for example, which is trained using semantic similarity between user-system dialogues, an astounding average success rate of 73% is achieved. This is a significant improvement over the baseline Proximal Policy Optimization (PPO), which has an average success rate of 60%. In addition, performance indicators such as booking rates and completion rates show a 10% rise over the baseline. Furthermore, these intrinsic incentive models help improve the system's policy's resilience in an increasing amount of domains. This implies that they could be useful in scaling up to settings that cover a wider range of domains.