 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Hacking as Equilibrium under Finite Evaluation
Mar 30, 2026We prove that under five minimal axioms -- multi-dimensional quality, finite evaluation, effective optimization, resource finiteness, and combinatorial interaction -- any optimized AI agent will systematically under-invest effort in quality dimensions not covered by its evaluation system. This result establishes reward hacking as a structural equilibrium, not a correctable bug, and holds regardless of the specific alignment method (RLHF, DPO, Constitutional AI, or others) or evaluation architecture employed. Our framework instantiates the multi-task principal-agent model of Holmstrom and Milgrom (1991) in the AI alignment setting, but exploits a structural feature unique to AI systems -- the known, differentiable architecture of reward models -- to derive a computable distortion index that predicts both the direction and severity of hacking on each quality dimension prior to deployment. We further prove that the transition from closed reasoning to agentic systems causes evaluation coverage to decline toward zero as tool count grows -- because quality dimensions expand combinatorially while evaluation costs grow at most linearly per tool -- so that hacking severity increases structurally and without bound. Our results unify the explanation of sycophancy, length gaming, and specification gaming under a single theoretical structure and yield an actionable vulnerability assessment procedure. We further conjecture -- with partial formal analysis -- the existence of a capability threshold beyond which agents transition from gaming within the evaluation system (Goodhart regime) to actively degrading the evaluation system itself (Campbell regime), providing the first economic formalization of Bostrom's (2014) "treacherous turn."
InFiConD: Interactive No-code Fine-tuning with Concept-based Knowledge Distillation
Jun 25, 2024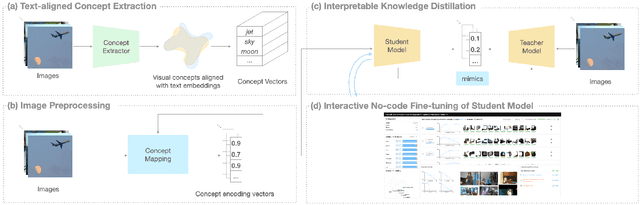
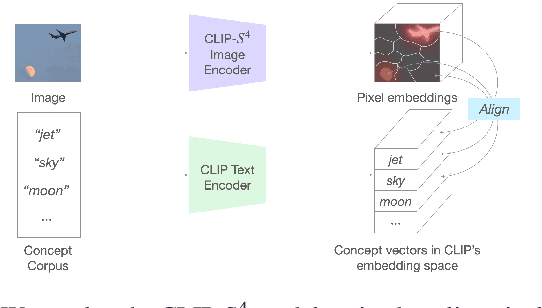
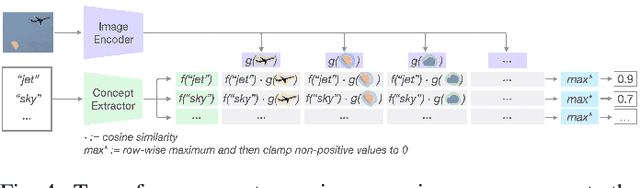
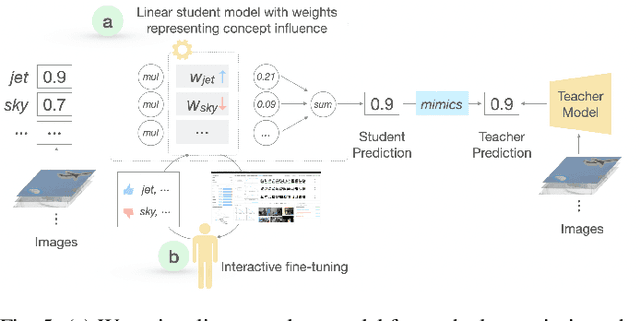
The emergence of large-scale pre-trained models has heightened their application in various downstream tasks, yet deployment is a challenge in environments with limited computational resources. Knowledge distillation has emerged as a solution in such scenarios, whereby knowledge from large teacher models is transferred into smaller student' models, but this is a non-trivial process that traditionally requires technical expertise in AI/ML. To address these challenges, this paper presents InFiConD, a novel framework that leverages visual concepts to implement the knowledge distillation process and enable subsequent no-code fine-tuning of student models. We develop a novel knowledge distillation pipeline based on extracting text-aligned visual concepts from a concept corpus using multimodal models, and construct highly interpretable linear student models based on visual concepts that mimic a teacher model in a response-based manner. InFiConD's interface allows users to interactively fine-tune the student model by manipulating concept influences directly in the user interface. We validate InFiConD via a robust usage scenario and user study. Our findings indicate that InFiConD's human-in-the-loop and visualization-driven approach enables users to effectively create and analyze student models, understand how knowledge is transferred, and efficiently perform fine-tuning operations. We discuss how this work highlights the potential of interactive and visual methods in making knowledge distillation and subsequent no-code fine-tuning more accessible and adaptable to a wider range of users with domain-specific demands.
ASAP: Interpretable Analysis and Summarization of AI-generated Image Patterns at Scale
Apr 03, 2024



Generative image models have emerged as a promising technology to produce realistic images. Despite potential benefits, concerns grow about its misuse, particularly in generating deceptive images that could raise significant ethical, legal, and societal issues. Consequently, there is growing demand to empower users to effectively discern and comprehend patterns of AI-generated images. To this end, we developed ASAP, an interactive visualization system that automatically extracts distinct patterns of AI-generated images and allows users to interactively explore them via various views. To uncover fake patterns, ASAP introduces a novel image encoder, adapted from CLIP, which transforms images into compact "distilled" representations, enriched with information for differentiating authentic and fake images. These representations generate gradients that propagate back to the attention maps of CLIP's transformer block. This process quantifies the relative importance of each pixel to image authenticity or fakeness, exposing key deceptive patterns. ASAP enables the at scale interactive analysis of these patterns through multiple, coordinated visualizations. This includes a representation overview with innovative cell glyphs to aid in the exploration and qualitative evaluation of fake patterns across a vast array of images, as well as a pattern view that displays authenticity-indicating patterns in images and quantifies their impact. ASAP supports the analysis of cutting-edge generative models with the latest architectures, including GAN-based models like proGAN and diffusion models like the latent diffusion model. We demonstrate ASAP's usefulness through two usage scenarios using multiple fake image detection benchmark datasets, revealing its ability to identify and understand hidden patterns in AI-generated images, especially in detecting fake human faces produced by diffusion-based techniques.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023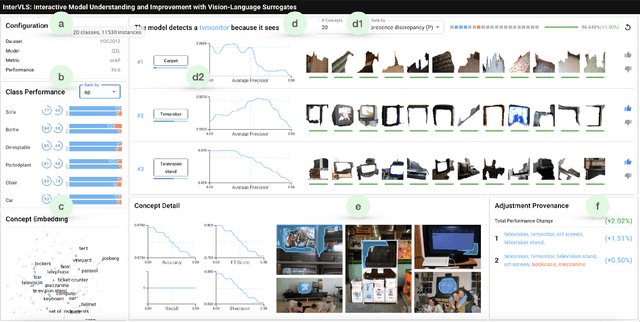
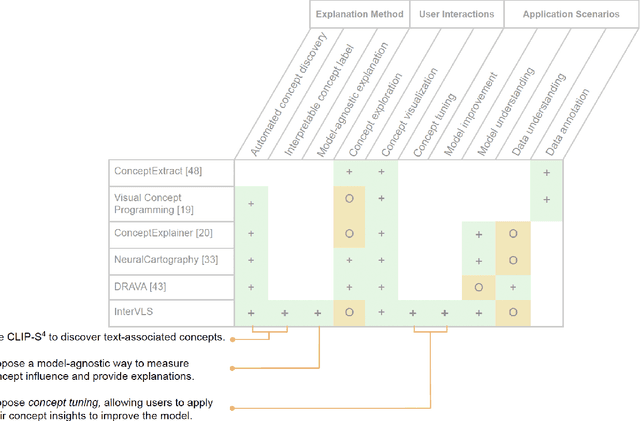
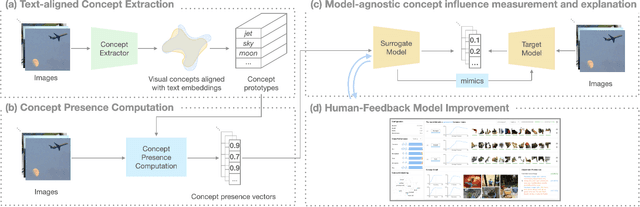
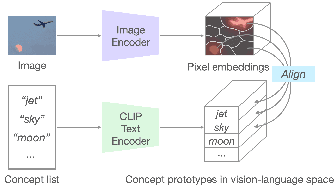
Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.