 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Upsampling as Statistical Shape Model for Pelvic
Jan 28, 2025



We propose a novel framework that integrates medical image segmentation and point cloud upsampling for accurate shape reconstruction of pelvic models. Using the SAM-Med3D model for segmentation and a point cloud upsampling network trained on the MedShapeNet dataset, our method transforms sparse medical imaging data into high-resolution 3D bone models. This framework leverages prior knowledge of anatomical shapes, achieving smoother and more complete reconstructions. Quantitative evaluations using metrics such as Chamfer Distance etc, demonstrate the effectiveness of the point cloud upsampling in pelvic model. Our approach offers potential applications in reconstructing other skeletal structures, providing a robust solution for medical image analysis and statistical shape modeling.
Representation Learning of Point Cloud Upsampling in Global and Local Inputs
Jan 13, 2025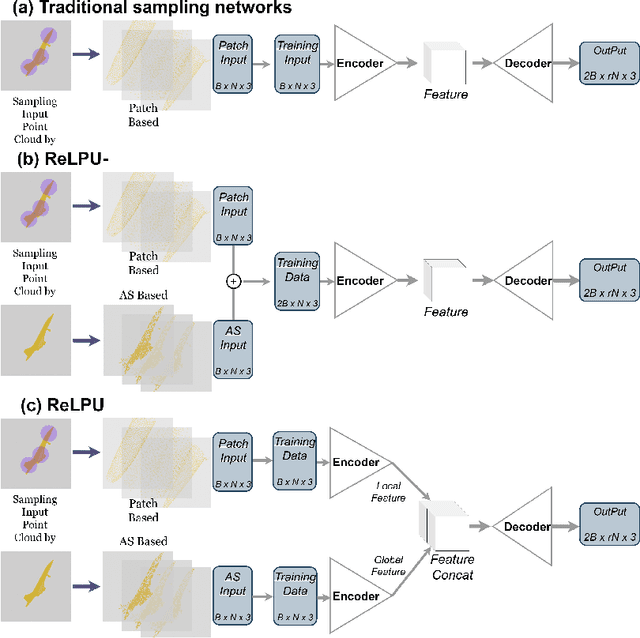
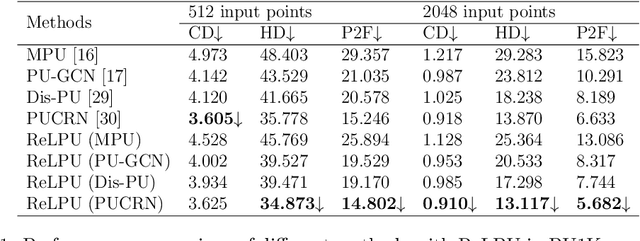
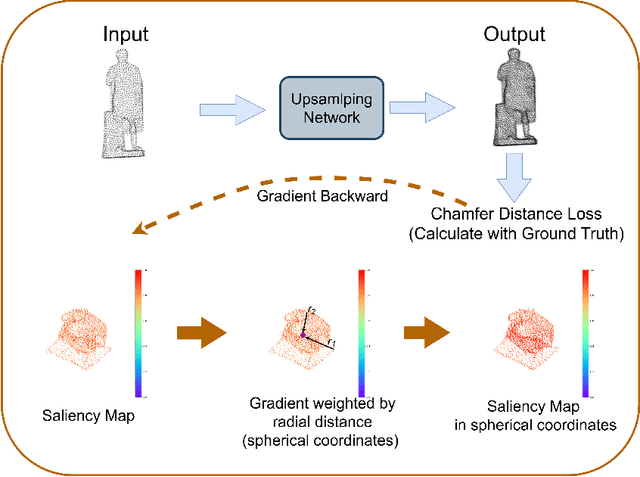
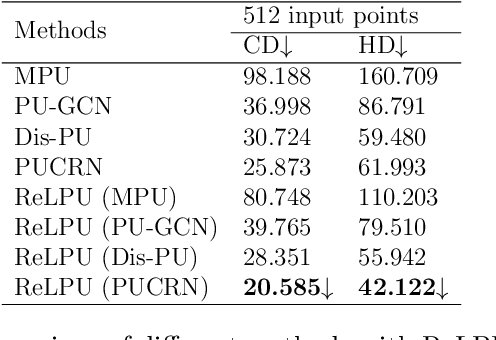
In recent years, point cloud upsampling has been widely applied in fields such as 3D reconstruction. Our study investigates the factors influencing point cloud upsampling on both global and local levels through representation learning. Specifically, the paper inputs global and local information of the same point cloud model object into two encoders to extract these features, fuses them, and then feeds the combined features into an upsampling decoder. The goal is to address issues of sparsity and noise in point clouds by leveraging prior knowledge from both global and local inputs. And the proposed framework can be applied to any state-of-the-art point cloud upsampling neural network. Experiments were conducted on a series of autoencoder-based models utilizing deep learning, yielding interpretability for both global and local inputs, and it has been proven in the results that our proposed framework can further improve the upsampling effect in previous SOTA works. At the same time, the Saliency Map reflects the differences between global and local feature inputs, as well as the effectiveness of training with both inputs in parallel.
Rethinking Data Input for Point Cloud Upsampling
Jul 05, 2024In recent years, point cloud upsampling has been widely applied in fields such as 3D reconstruction and surface generation. However, existing point cloud upsampling inputs are all patch based, and there is no research discussing the differences and principles between point cloud model full input and patch based input. In order to compare with patch based point cloud input, this article proposes a new data input method, which divides the full point cloud model to ensure shape integrity while training PU-GCN. This article was validated on the PU1K and ABC datasets, but the results showed that Patch based performance is better than model based full input i.e. Average Segment input. Therefore, this article explores the data input factors and model modules that affect the upsampling results of point clouds.
Contrastive Learning for Sleep Staging based on Inter Subject Correlation
May 05, 2023In recent years, multitudes of researches have applied deep learning to automatic sleep stage classification. Whereas actually, these works have paid less attention to the issue of cross-subject in sleep staging. At the same time, emerging neuroscience theories on inter-subject correlations can provide new insights for cross-subject analysis. This paper presents the MViTime model that have been used in sleep staging study. And we implement the inter-subject correlation theory through contrastive learning, providing a feasible solution to address the cross-subject problem in sleep stage classification. Finally, experimental results and conclusions are presented, demonstrating that the developed method has achieved state-of-the-art performance on sleep staging. The results of the ablation experiment also demonstrate the effectiveness of the cross-subject approach based on contrastive learning.