 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Matrix Factorization Methods for Pre-trained Transformers
Paper and Code
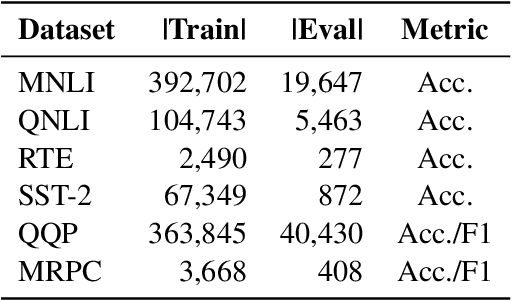
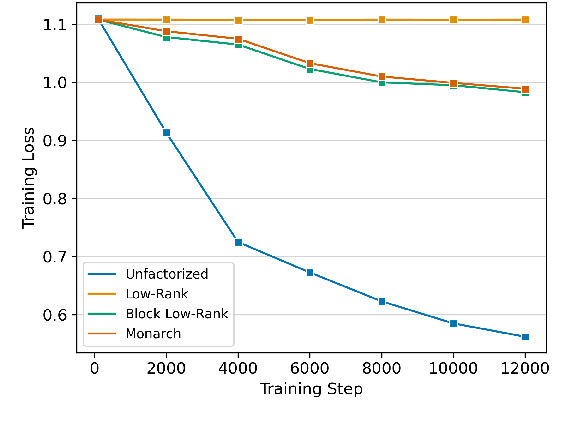
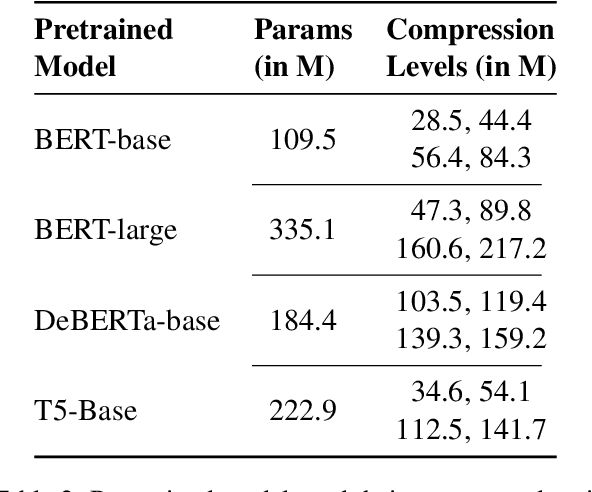
The increasing size of transformer-based models in NLP makes the question of compressing them important. In this work, we present a comprehensive analysis of factorization based model compression techniques. Specifically, we focus on comparing straightforward low-rank factorization against the recently introduced Monarch factorization, which exhibits impressive performance preservation on the GLUE benchmark. To mitigate stability issues associated with low-rank factorization of the matrices in pre-trained transformers, we introduce a staged factorization approach wherein layers are factorized one by one instead of being factorized simultaneously. Through this strategy we significantly enhance the stability and reliability of the compression process. Further, we introduce a simple block-wise low-rank factorization method, which has a close relationship to Monarch factorization. Our experiments lead to the surprising conclusion that straightforward low-rank factorization consistently outperforms Monarch factorization across both different compression ratios and six different text classification tasks.