 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Document Financial Question Answering using LLMs
Nov 08, 2024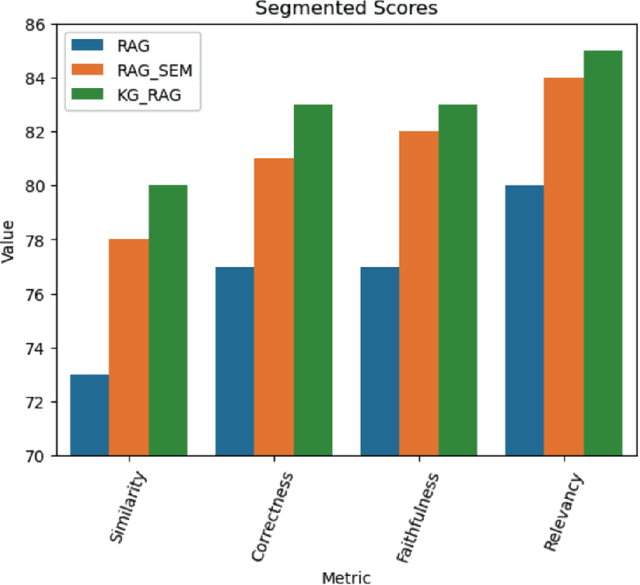
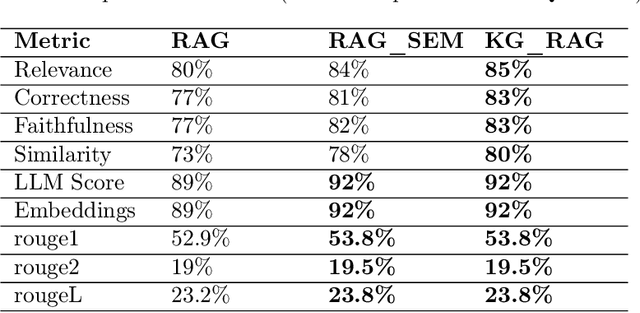
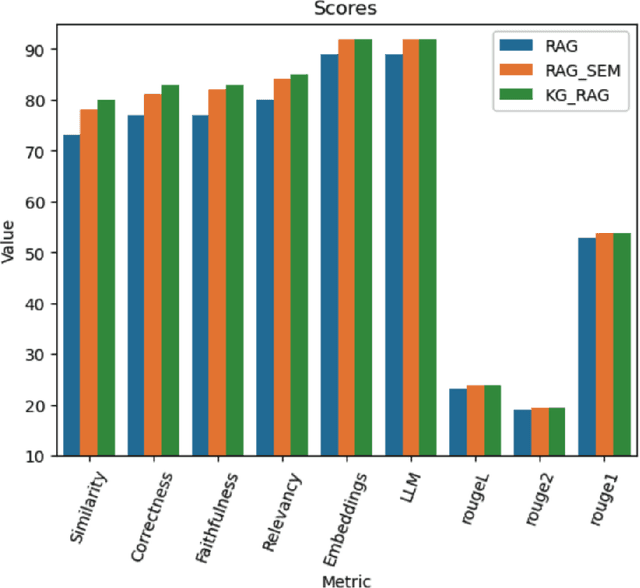
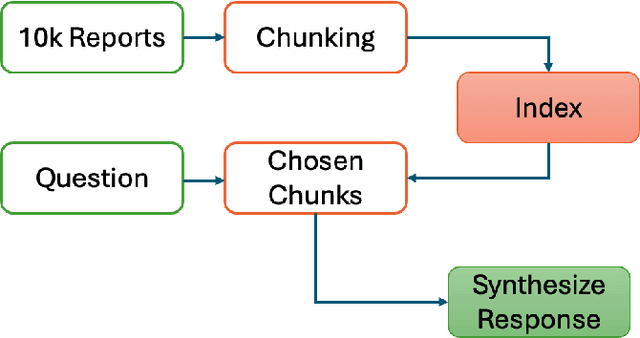
We propose two new methods for multi-document financial question answering. First, a method that uses semantic tagging, and then, queries the index to get the context (RAG_SEM). And second, a Knowledge Graph (KG_RAG) based method that uses semantic tagging, and, retrieves knowledge graph triples from a graph database, as context. KG_RAG uses knowledge graphs constructed using a small model that is fine-tuned using knowledge distillation using a large teacher model. The data consists of 18 10K reports of Apple, Microsoft, Alphabet, NVIDIA, Amazon and Tesla for the years 2021, 2022 and 2023. The list of questions in the data consists of 111 complex questions including many esoteric questions that are difficult to answer and the answers are not completely obvious. As evaluation metrics, we use overall scores as well as segmented scores for measurement including the faithfulness, relevance, correctness, similarity, an LLM based overall score and the rouge scores as well as a similarity of embeddings. We find that both methods outperform plain RAG significantly. KG_RAG outperforms RAG_SEM in four out of nine metrics.
Enhancing Question Answering on Charts Through Effective Pre-training Tasks
Jun 14, 2024



To completely understand a document, the use of textual information is not enough. Understanding visual cues, such as layouts and charts, is also required. While the current state-of-the-art approaches for document understanding (both OCR-based and OCR-free) work well, a thorough analysis of their capabilities and limitations has not yet been performed. Therefore, in this work, we addresses the limitation of current VisualQA models when applied to charts and plots. To investigate shortcomings of the state-of-the-art models, we conduct a comprehensive behavioral analysis, using ChartQA as a case study. Our findings indicate that existing models particularly underperform in answering questions related to the chart's structural and visual context, as well as numerical information. To address these issues, we propose three simple pre-training tasks that enforce the existing model in terms of both structural-visual knowledge, as well as its understanding of numerical questions. We evaluate our pre-trained model (called MatCha-v2) on three chart datasets - both extractive and abstractive question datasets - and observe that it achieves an average improvement of 1.7% over the baseline model.
ULTRA: Unleash LLMs' Potential for Event Argument Extraction through Hierarchical Modeling and Pair-wise Refinement
Jan 24, 2024


Structural extraction of events within discourse is critical since it avails a deeper understanding of communication patterns and behavior trends. Event argument extraction (EAE), at the core of event-centric understanding, is the task of identifying role-specific text spans (i.e., arguments) for a given event. Document-level EAE (DocEAE) focuses on arguments that are scattered across an entire document. In this work, we explore the capabilities of open source Large Language Models (LLMs), i.e., Flan-UL2, for the DocEAE task. To this end, we propose ULTRA, a hierarchical framework that extracts event arguments more cost-effectively -- the method needs as few as 50 annotations and doesn't require hitting costly API endpoints. Further, it alleviates the positional bias issue intrinsic to LLMs. ULTRA first sequentially reads text chunks of a document to generate a candidate argument set, upon which ULTRA learns to drop non-pertinent candidates through self-refinement. We further introduce LEAFER to address the challenge LLMs face in locating the exact boundary of an argument span. ULTRA outperforms strong baselines, which include strong supervised models and ChatGPT, by 9.8% when evaluated by the exact match (EM) metric.
Don't Retrain, Just Rewrite: Countering Adversarial Perturbations by Rewriting Text
May 25, 2023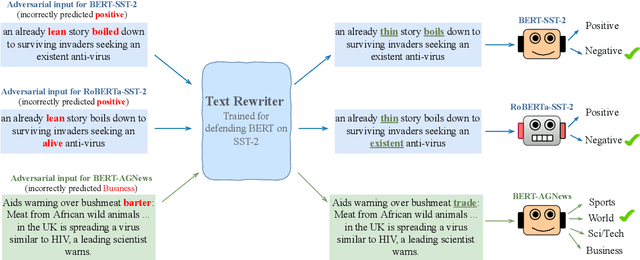
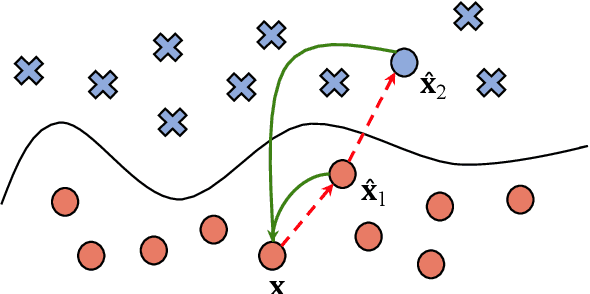
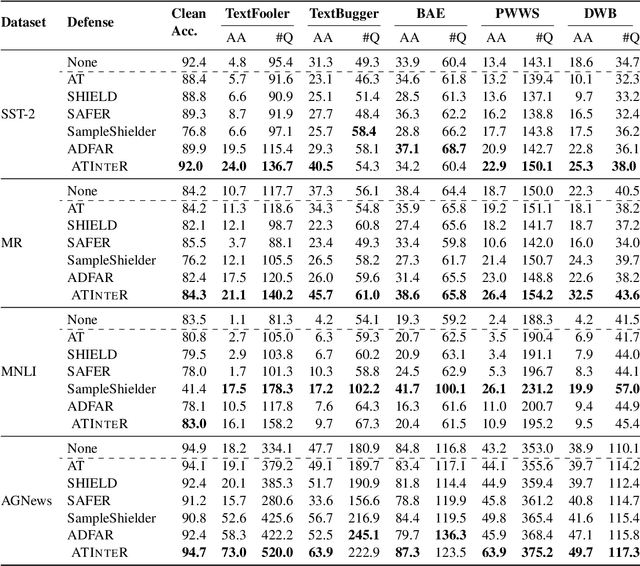
Can language models transform inputs to protect text classifiers against adversarial attacks? In this work, we present ATINTER, a model that intercepts and learns to rewrite adversarial inputs to make them non-adversarial for a downstream text classifier. Our experiments on four datasets and five attack mechanisms reveal that ATINTER is effective at providing better adversarial robustness than existing defense approaches, without compromising task accuracy. For example, on sentiment classification using the SST-2 dataset, our method improves the adversarial accuracy over the best existing defense approach by more than 4% with a smaller decrease in task accuracy (0.5% vs 2.5%). Moreover, we show that ATINTER generalizes across multiple downstream tasks and classifiers without having to explicitly retrain it for those settings. Specifically, we find that when ATINTER is trained to remove adversarial perturbations for the sentiment classification task on the SST-2 dataset, it even transfers to a semantically different task of news classification (on AGNews) and improves the adversarial robustness by more than 10%.
Multi-Task Learning of Query Intent and Named Entities using Transfer Learning
Apr 28, 2021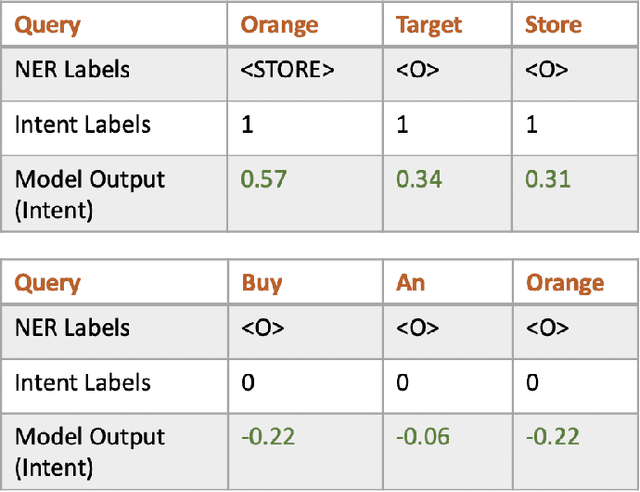

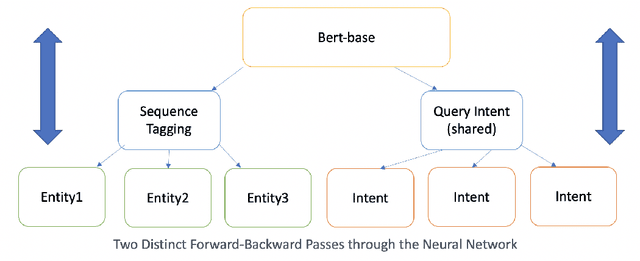
Named entity recognition (NER) has been studied extensively and the earlier algorithms were based on sequence labeling like Hidden Markov Models (HMM) and conditional random fields (CRF). These were followed by neural network based deep learning models. Recently, BERT has shown new state of the art accuracy in sequence labeling tasks like NER. In this short article, we study various approaches to task specific NER. Task specific NER has two components - identifying the intent of a piece of text (like search queries), and then labeling the query with task specific named entities. For example, we consider the task of labeling Target store locations in a search query (which could be entered in a search box or spoken in a device like Alexa or Google Home). Store locations are highly ambiguous and sometimes it is difficult to differentiate between say a location and a non-location. For example, "pickup my order at orange store" has "orange" as the store location, while "buy orange at target" has "orange" as a fruit. We explore this difficulty by doing multi-task learning which we call global to local transfer of information. We jointly learn the query intent (i.e. store lookup) and the named entities by using multiple loss functions in our BERT based model and find interesting results.
Analysis of Greenhouse Gases
Apr 17, 2020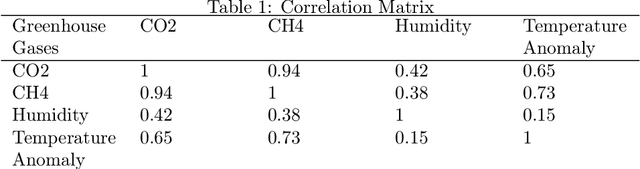
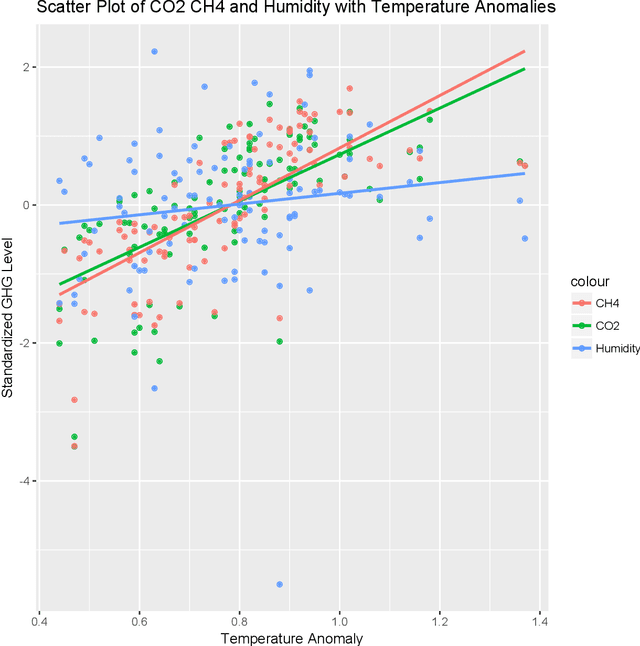

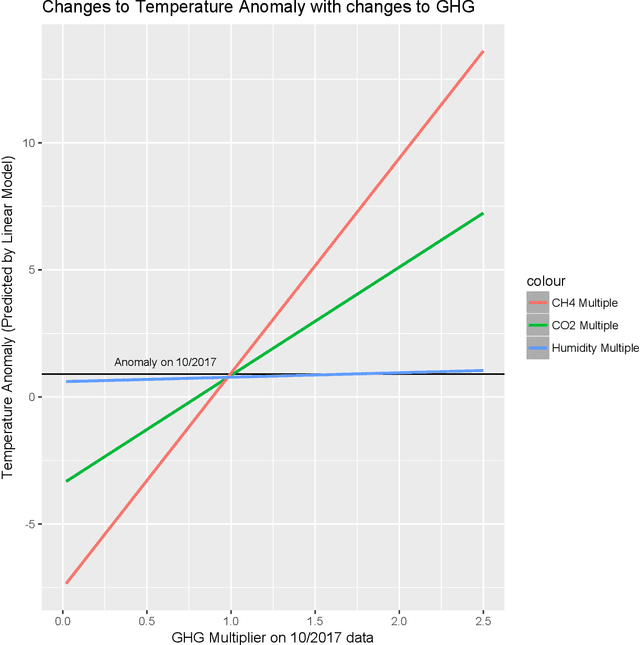
Climate change is a result of a complex system of interactions of greenhouse gases (GHG), the ocean, land, ice, and clouds. Large climate change models use several computers and solve several equations to predict the future climate. The equations may include simple polynomials to partial differential equations. Because of the uptake mechanism of the land and ocean, greenhouse gas emissions can take a while to affect the climate. The IPCC has published reports on how greenhouse gas emissions may affect the average temperature of the troposphere and the predictions show that by the end of the century, we can expect a temperature increase from 0.8 C to 5 C. In this article, I use Linear Regression (LM), Quadratic Regression and Gaussian Process Regression (GPR) on monthly GHG data going back several years and try to predict the temperature anomalies based on extrapolation. The results are quite similar to the IPCC reports.
Hebbian Graph Embeddings
Sep 10, 2019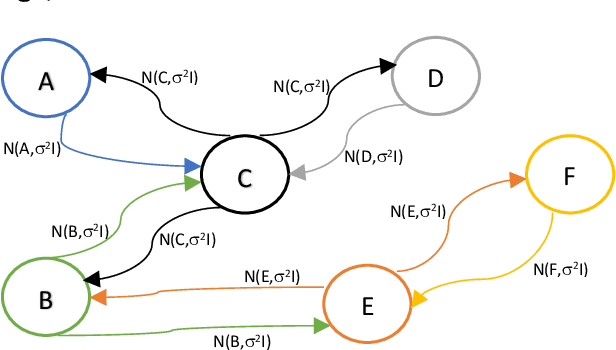
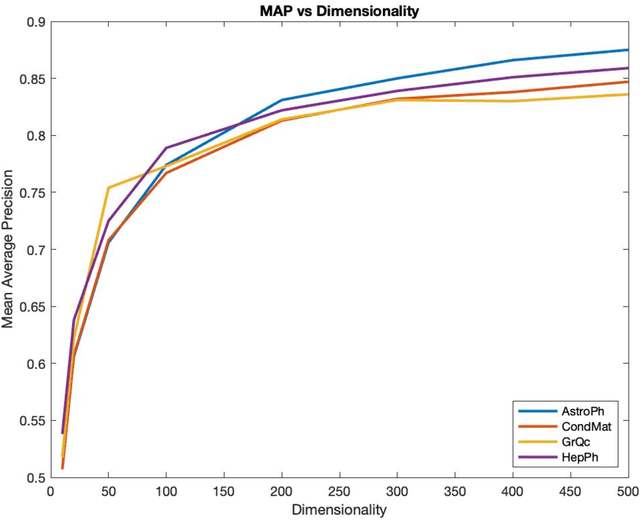
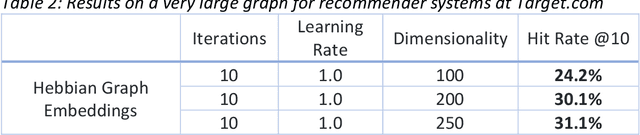
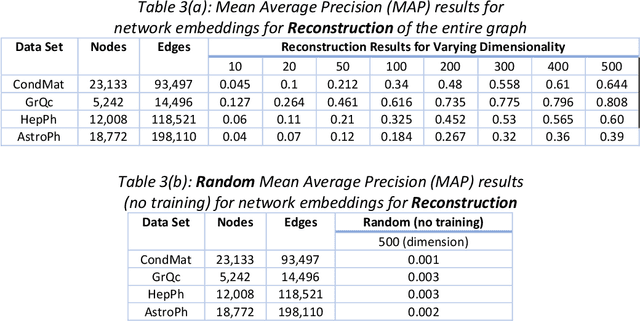
Representation learning has recently been successfully used to create vector representations of entities in language learning, recommender systems and in similarity learning. Graph embeddings exploit the locality structure of a graph and generate embeddings for nodes which could be words in a language, products of a retail website; and the nodes are connected based on a context window. In this paper, we consider graph embeddings with an error-free associative learning update rule, which models the embedding vector of node as a non-convex Gaussian mixture of the embeddings of the nodes in its immediate vicinity with some constant variance that is reduced as iterations progress. It is very easy to parallelize our algorithm without any form of shared memory, which makes it possible to use it on very large graphs with a much higher dimensionality of the embeddings. Results show that our algorithm performs well when the dimensionality of the embeddings is large.
Model Adaptation via Model Interpolation and Boosting for Web Search Ranking
Jul 22, 2019
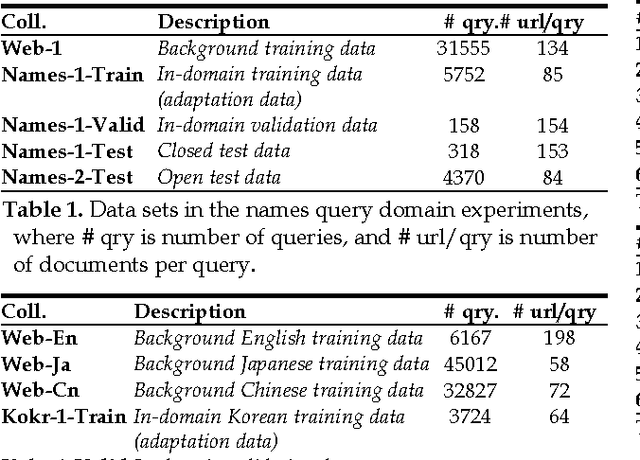


This paper explores two classes of model adaptation methods for Web search ranking: Model Interpolation and error-driven learning approaches based on a boosting algorithm. The results show that model interpolation, though simple, achieves the best results on all the open test sets where the test data is very different from the training data. The tree-based boosting algorithm achieves the best performance on most of the closed test sets where the test data and the training data are similar, but its performance drops significantly on the open test sets due to the instability of trees. Several methods are explored to improve the robustness of the algorithm, with limited success.
Genetic Algorithm for the 0/1 Multidimensional Knapsack Problem
Jul 20, 2019
The 0/1 multidimensional knapsack problem is the 0/1 knapsack problem with m constraints which makes it difficult to solve using traditional methods like dynamic programming or branch and bound algorithms. We present a genetic algorithm for the multidimensional knapsack problem with Java code that is able to solve publicly available instances in a very short computational duration. Our algorithm uses iteratively computed Lagrangian multipliers as constraint weights to augment the greedy algorithm for the multidimensional knapsack problem and uses that information in a greedy crossover in a genetic algorithm. The algorithm uses several other hyperparameters which can be set in the code to control convergence. Our algorithm improves upon the algorithm by Chu and Beasley in that it converges to optimum or near optimum solutions much faster.
Genetic Algorithm for a class of Knapsack Problems
Feb 15, 2019The 0/1 knapsack problem is weakly NP-hard in that there exist pseudo-polynomial time algorithms based on dynamic programming that can solve it exactly. There are also the core branch and bound algorithms that can solve large randomly generated instances in a very short amount of time. However, as the correlation between the variables is increased, the difficulty of the problem increases. Recently a new class of knapsack problems was introduced by D. Pisinger called the spanner knapsack instances. These instances are unsolvable by the core branch and bound instances; and as the size of the coefficients and the capacity constraint increase, the spanner instances are unsolvable even by dynamic programming based algorithms. In this paper, a genetic algorithm is presented for spanner knapsack instances. Results show that the algorithm is capable of delivering optimum solutions within a reasonable amount of computational duration.