 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Lie: How Reasoning Leads to Honesty
Mar 16, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Think Before You Lie: How Reasoning Improves Honesty
Mar 10, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
ULTRA: Unleash LLMs' Potential for Event Argument Extraction through Hierarchical Modeling and Pair-wise Refinement
Jan 24, 2024


Structural extraction of events within discourse is critical since it avails a deeper understanding of communication patterns and behavior trends. Event argument extraction (EAE), at the core of event-centric understanding, is the task of identifying role-specific text spans (i.e., arguments) for a given event. Document-level EAE (DocEAE) focuses on arguments that are scattered across an entire document. In this work, we explore the capabilities of open source Large Language Models (LLMs), i.e., Flan-UL2, for the DocEAE task. To this end, we propose ULTRA, a hierarchical framework that extracts event arguments more cost-effectively -- the method needs as few as 50 annotations and doesn't require hitting costly API endpoints. Further, it alleviates the positional bias issue intrinsic to LLMs. ULTRA first sequentially reads text chunks of a document to generate a candidate argument set, upon which ULTRA learns to drop non-pertinent candidates through self-refinement. We further introduce LEAFER to address the challenge LLMs face in locating the exact boundary of an argument span. ULTRA outperforms strong baselines, which include strong supervised models and ChatGPT, by 9.8% when evaluated by the exact match (EM) metric.
CoordiQ : Coordinated Q-learning for Electric Vehicle Charging Recommendation
Jan 28, 2021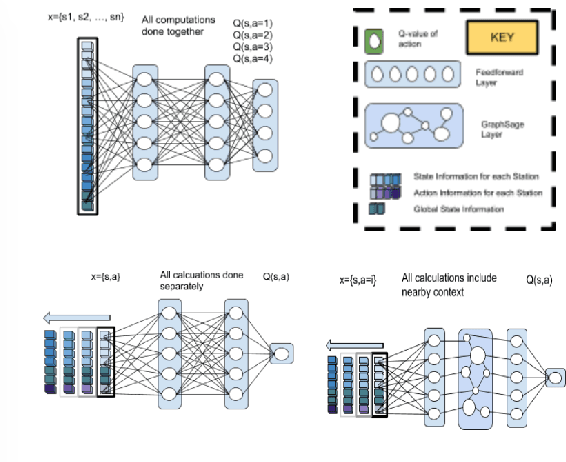


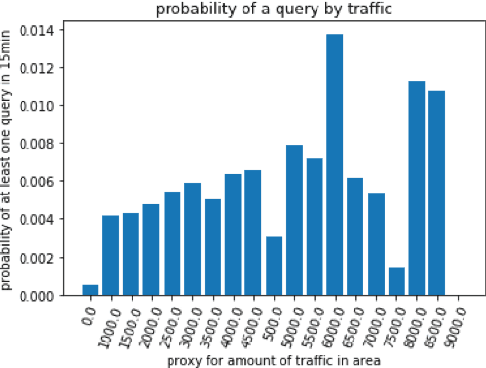
Electric vehicles have been rapidly increasing in usage, but stations to charge them have not always kept up with demand, so efficient routing of vehicles to stations is critical to operating at maximum efficiency. Deciding which stations to recommend drivers to is a complex problem with a multitude of possible recommendations, volatile usage patterns and temporally extended consequences of recommendations. Reinforcement learning offers a powerful paradigm for solving sequential decision-making problems, but traditional methods may struggle with sample efficiency due to the high number of possible actions. By developing a model that allows complex representations of actions, we improve outcomes for users of our system by over 30% when compared to existing baselines in a simulation. If implemented widely, these better recommendations can globally save over 4 million person-hours of waiting and driving each year.