 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Multi-Armed Bandits with Limited Control Variates
Mar 02, 2026Motivated by wireless networks where interference or channel state estimates provide partial insight into throughput, we study a variant of the classical stochastic multi-armed bandit problem in which the learner has limited access to auxiliary information. Recent work has shown that such auxiliary information, when available as control variates, can be used to get tighter confidence bounds, leading to lower regret. However, existing works assume that control variates are available in every round, which may not be realistic in several real-life scenarios. To address this, we propose UCB-LCV, an upper confidence bound (UCB) based algorithm that effectively combines the estimators obtained from rewards and control variates. When there is no control variate, UCB-LCV leads to a novel algorithm that we call UCB-NORMAL, outperforming its existing algorithms for the standard MAB setting with normally distributed rewards. Finally, we discuss variants of the proposed UCB-LCV that apply to general distributions and experimentally demonstrate that UCB-LCV outperforms existing bandit algorithms.
FastFlow: Accelerating The Generative Flow Matching Models with Bandit Inference
Feb 11, 2026Flow-matching models deliver state-of-the-art fidelity in image and video generation, but the inherent sequential denoising process renders them slower. Existing acceleration methods like distillation, trajectory truncation, and consistency approaches are static, require retraining, and often fail to generalize across tasks. We propose FastFlow, a plug-and-play adaptive inference framework that accelerates generation in flow matching models. FastFlow identifies denoising steps that produce only minor adjustments to the denoising path and approximates them without using the full neural network models used for velocity predictions. The approximation utilizes finite-difference velocity estimates from prior predictions to efficiently extrapolate future states, enabling faster advancements along the denoising path at zero compute cost. This enables skipping computation at intermediary steps. We model the decision of how many steps to safely skip before requiring a full model computation as a multi-armed bandit problem. The bandit learns the optimal skips to balance speed with performance. FastFlow integrates seamlessly with existing pipelines and generalizes across image generation, video generation, and editing tasks. Experiments demonstrate a speedup of over 2.6x while maintaining high-quality outputs. The source code for this work can be found at https://github.com/Div290/FastFlow.
FlowCast: Trajectory Forecasting for Scalable Zero-Cost Speculative Flow Matching
Feb 01, 2026Flow Matching (FM) has recently emerged as a powerful approach for high-quality visual generation. However, their prohibitively slow inference due to a large number of denoising steps limits their potential use in real-time or interactive applications. Existing acceleration methods, like distillation, truncation, or consistency training, either degrade quality, incur costly retraining, or lack generalization. We propose FlowCast, a training-free speculative generation framework that accelerates inference by exploiting the fact that FM models are trained to preserve constant velocity. FlowCast speculates future velocity by extrapolating current velocity without incurring additional time cost, and accepts it if it is within a mean-squared error threshold. This constant-velocity forecasting allows redundant steps in stable regions to be aggressively skipped while retaining precision in complex ones. FlowCast is a plug-and-play framework that integrates seamlessly with any FM model and requires no auxiliary networks. We also present a theoretical analysis and bound the worst-case deviation between speculative and full FM trajectories. Empirical evaluations demonstrate that FlowCast achieves $>2.5\times$ speedup in image generation, video generation, and editing tasks, outperforming existing baselines with no quality loss as compared to standard full generation.
FastVLM: Self-Speculative Decoding for Fast Vision-Language Model Inference
Oct 26, 2025Vision-language Models (VLMs) have made significant strides in visual understanding and query response generation, but often face challenges of high computational cost and inference latency due to autoregressive decoding. In this work, we introduce an imitation-learning-based Self-Speculative Decoding (SSD) framework, named FastVLM, to address these limitations. Our approach employs a lightweight draft model for token generation in an autoregressive manner, while a full model verifies these tokens non-autoregressively. Accepted tokens proceed seamlessly, while rejected tokens are corrected by the full model and used to guide the draft model's refinement. Through an imitation network, FastVLM enhances the draft model by integrating deeper level insights from the full model's architecture. Also, it maintains the performance integrity of the full model while training the draft model, achieving a balance between efficiency and accuracy. Our method speeds up the inference process by 1.55-1.85x as compared to the final layer with minimal loss in performance.
FREE: Fast and Robust Vision Language Models with Early Exits
Jun 07, 2025In recent years, Vision-Language Models (VLMs) have shown remarkable performance improvements in Vision-Language tasks. However, their large size poses challenges for real-world applications where inference latency is a concern. To tackle this issue, we propose employing Early Exit (EE) strategies in VLMs. However, training exit classifiers in VLMs is challenging, particularly with limited labeled training data. To address this, we introduce FREE, an adversarial training approach within a GAN-based framework. Here, each exit consists of a transformer layer and a classifier. The transformer layer is adversarially trained to produce feature representations similar to the final layer, while a feature classifier serves as the discriminator. Our method focuses on performing input-adaptive inference that increases inference speed with minimal drop in performance. Experimental results demonstrate the effectiveness of our approach in enhancing accuracy and model robustness by mitigating overthinking and the phenomenon of mid-crisis that we highlight. We experimentally validate that our method speeds up the inference process by more than 1.51x while retaining comparable performance. The source code is available at https://github.com/Div290/FREE.
BEEM: Boosting Performance of Early Exit DNNs using Multi-Exit Classifiers as Experts
Feb 02, 2025



Early Exit (EE) techniques have emerged as a means to reduce inference latency in Deep Neural Networks (DNNs). The latency improvement and accuracy in these techniques crucially depend on the criteria used to make exit decisions. We propose a new decision criterion where exit classifiers are treated as experts BEEM and aggregate their confidence scores. The confidence scores are aggregated only if neighbouring experts are consistent in prediction as the samples pass through them, thus capturing their ensemble effect. A sample exits when the aggregated confidence value exceeds a threshold. The threshold is set using the error rates of the intermediate exits aiming to surpass the performance of conventional DNN inference. Experimental results on the COCO dataset for Image captioning and GLUE datasets for various language tasks demonstrate that our method enhances the performance of state-of-the-art EE methods, achieving improvements in speed-up by a factor 1.5x to 2.1x. When compared to the final layer, its accuracy is comparable in harder Image Captioning and improves in the easier language tasks. The source code for this work is publicly available at https://github.com/Div290/BEEM1/tree/main
A Survey of Early Exit Deep Neural Networks in NLP
Jan 13, 2025



Deep Neural Networks (DNNs) have grown increasingly large in size to achieve state of the art performance across a wide range of tasks. However, their high computational requirements make them less suitable for resource-constrained applications. Also, real-world datasets often consist of a mixture of easy and complex samples, necessitating adaptive inference mechanisms that account for sample difficulty. Early exit strategies offer a promising solution by enabling adaptive inference, where simpler samples are classified using the initial layers of the DNN, thereby accelerating the overall inference process. By attaching classifiers at different layers, early exit methods not only reduce inference latency but also improve the model robustness against adversarial attacks. This paper presents a comprehensive survey of early exit methods and their applications in NLP.
Distributed Inference on Mobile Edge and Cloud: An Early Exit based Clustering Approach
Oct 06, 2024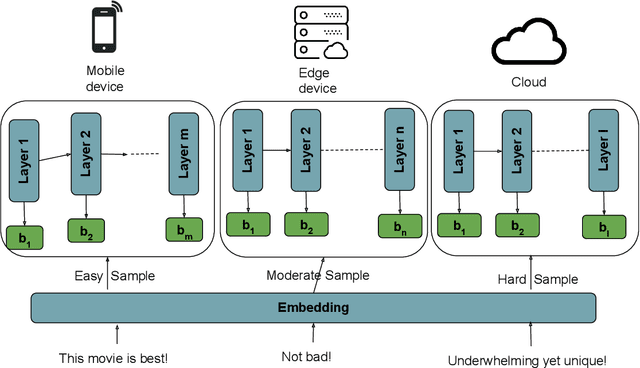

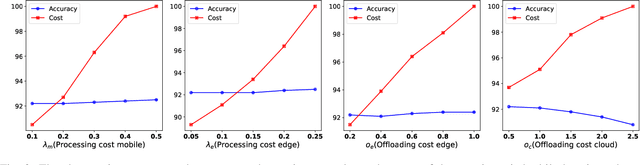
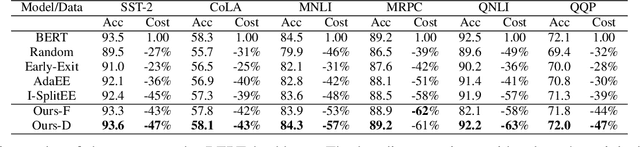
Recent advances in Deep Neural Networks (DNNs) have demonstrated outstanding performance across various domains. However, their large size is a challenge for deployment on resource-constrained devices such as mobile, edge, and IoT platforms. To overcome this, a distributed inference setup can be used where a small-sized DNN (initial few layers) can be deployed on mobile, a bigger version on the edge, and the full-fledged, on the cloud. A sample that has low complexity (easy) could be then inferred on mobile, that has moderate complexity (medium) on edge, and higher complexity (hard) on the cloud. As the complexity of each sample is not known beforehand, the following question arises in distributed inference: how to decide complexity so that it is processed by enough layers of DNNs. We develop a novel approach named DIMEE that utilizes Early Exit (EE) strategies developed to minimize inference latency in DNNs. DIMEE aims to improve the accuracy, taking into account the offloading cost from mobile to edge/cloud. Experimental validation on GLUE datasets, encompassing various NLP tasks, shows that our method significantly reduces the inference cost (> 43%) while maintaining a minimal drop in accuracy (< 0.3%) compared to the case where all the inference is made in cloud.
CAPEEN: Image Captioning with Early Exits and Knowledge Distillation
Oct 06, 2024
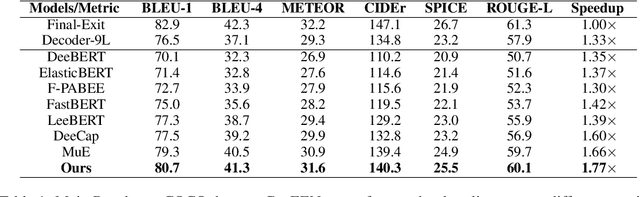

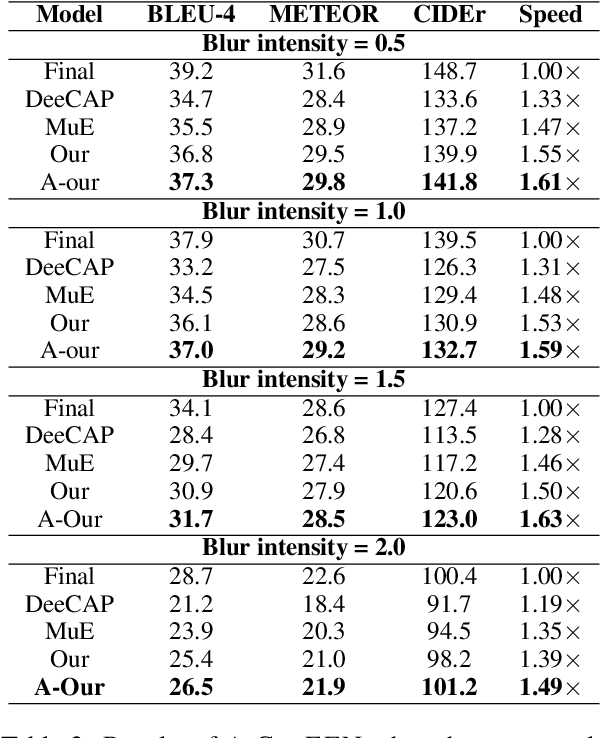
Deep neural networks (DNNs) have made significant progress in recognizing visual elements and generating descriptive text in image-captioning tasks. However, their improved performance comes from increased computational burden and inference latency. Early Exit (EE) strategies can be used to enhance their efficiency, but their adaptation presents challenges in image captioning as it requires varying levels of semantic information for accurate predictions. To overcome this, we introduce CAPEEN to improve the performance of EE strategies using knowledge distillation. Inference in CAPEEN is completed at intermediary layers if prediction confidence exceeds a predefined value learned from the training data. To account for real-world deployments, where target distributions could drift from that of training samples, we introduce a variant A-CAPEEN to adapt the thresholds on the fly using Multiarmed bandits framework. Experiments on the MS COCO and Flickr30k datasets show that CAPEEN gains speedup of 1.77x while maintaining competitive performance compared to the final layer, and A-CAPEEN additionally offers robustness against distortions. The source code is available at https://github.com/Div290/CapEEN
DAdEE: Unsupervised Domain Adaptation in Early Exit PLMs
Oct 06, 2024



Pre-trained Language Models (PLMs) exhibit good accuracy and generalization ability across various tasks using self-supervision, but their large size results in high inference latency. Early Exit (EE) strategies handle the issue by allowing the samples to exit from classifiers attached to the intermediary layers, but they do not generalize well, as exit classifiers can be sensitive to domain changes. To address this, we propose Unsupervised Domain Adaptation in EE framework (DADEE) that employs multi-level adaptation using knowledge distillation. DADEE utilizes GAN-based adversarial adaptation at each layer to achieve domain-invariant representations, reducing the domain gap between the source and target domain across all layers. The attached exits not only speed up inference but also enhance domain adaptation by reducing catastrophic forgetting and mode collapse, making it more suitable for real-world scenarios. Experiments on tasks such as sentiment analysis, entailment classification, and natural language inference demonstrate that DADEE consistently outperforms not only early exit methods but also various domain adaptation methods under domain shift scenarios. The anonymized source code is available at https://github.com/Div290/DAdEE.