 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Inference on Mobile Edge and Cloud: An Early Exit based Clustering Approach
Paper and Code
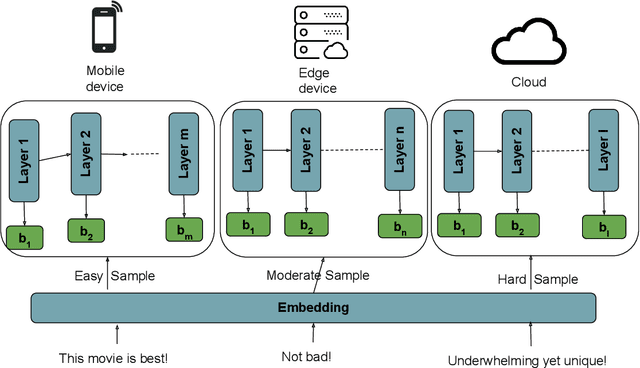

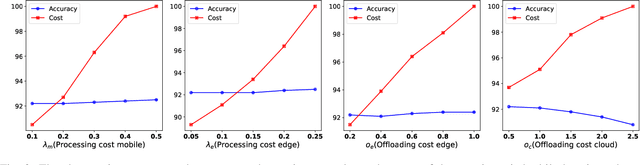
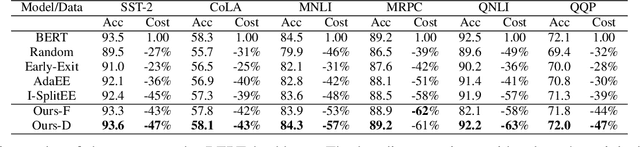
Recent advances in Deep Neural Networks (DNNs) have demonstrated outstanding performance across various domains. However, their large size is a challenge for deployment on resource-constrained devices such as mobile, edge, and IoT platforms. To overcome this, a distributed inference setup can be used where a small-sized DNN (initial few layers) can be deployed on mobile, a bigger version on the edge, and the full-fledged, on the cloud. A sample that has low complexity (easy) could be then inferred on mobile, that has moderate complexity (medium) on edge, and higher complexity (hard) on the cloud. As the complexity of each sample is not known beforehand, the following question arises in distributed inference: how to decide complexity so that it is processed by enough layers of DNNs. We develop a novel approach named DIMEE that utilizes Early Exit (EE) strategies developed to minimize inference latency in DNNs. DIMEE aims to improve the accuracy, taking into account the offloading cost from mobile to edge/cloud. Experimental validation on GLUE datasets, encompassing various NLP tasks, shows that our method significantly reduces the inference cost (> 43%) while maintaining a minimal drop in accuracy (< 0.3%) compared to the case where all the inference is made in cloud.